
Benchmarks for ChatGPT and Co
January 2024
The highlights of the month:
Mistral 7B OpenChat v3 (0106) finally beats ChatGPT-3.5 v1
Why we did not include Mixtral 8x7B and Mistral-Medium in the benchmark
Your ideas are in demand! Which tasks would you like to see in our benchmarks?
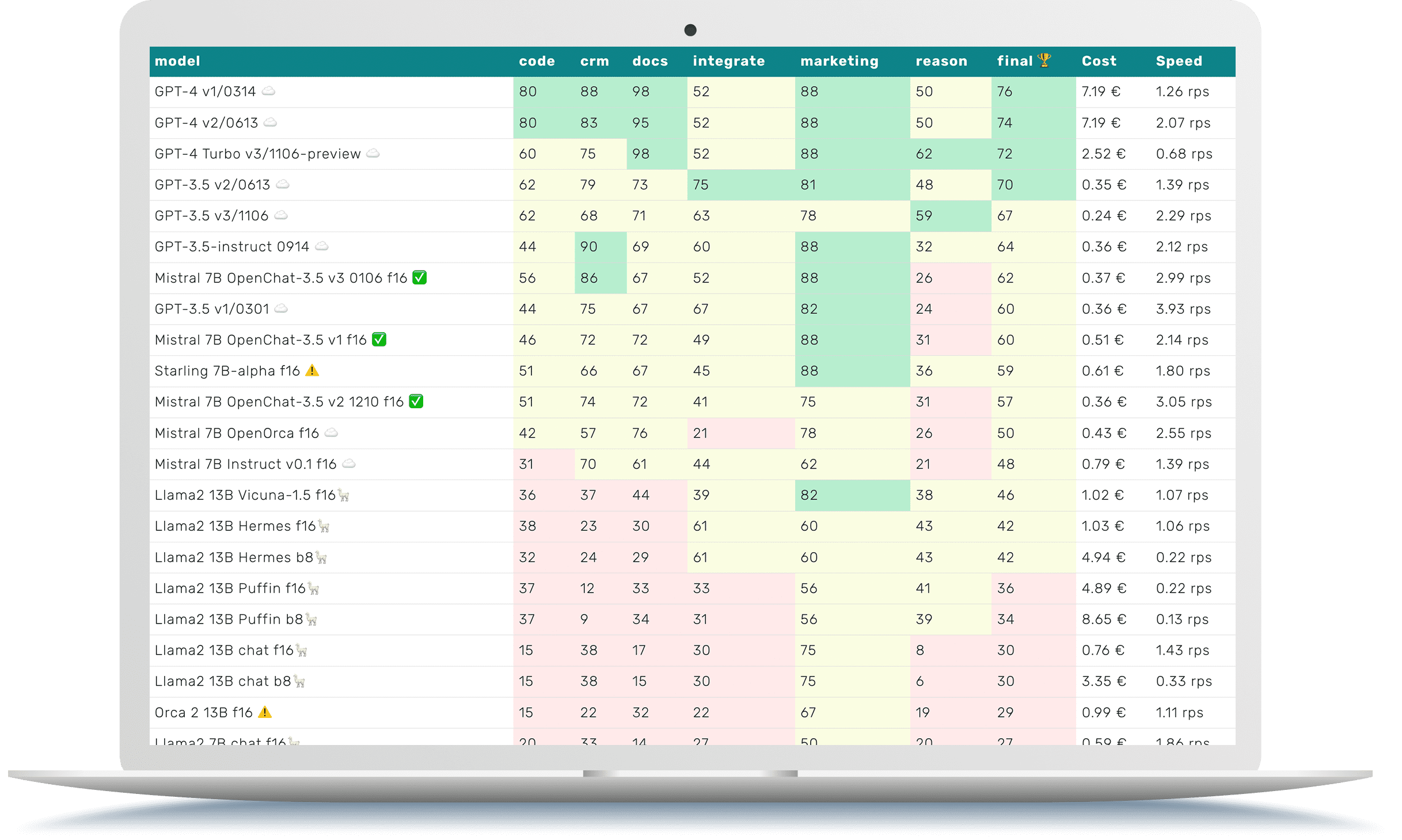
LLM Benchmarks | January 2024
The Trustbit benchmarks evaluate the models in terms of their suitability for digital product development. The higher the score, the better.
☁️ - Cloud models with proprietary license
✅ - Open source models that can be run locally without restrictions
🦙 - Local models with Llama license
| model | code | crm | docs | integrate | marketing | reason | final 🏆 | Cost | Speed |
|---|---|---|---|---|---|---|---|---|---|
| GPT-4 v1/0314 ☁️ | 80 | 88 | 98 | 52 | 88 | 50 | 76 | 7.19 € | 1.26 rps |
| GPT-4 v2/0613 ☁️ | 80 | 83 | 95 | 52 | 88 | 50 | 74 | 7.19 € | 2.07 rps |
| GPT-4 Turbo v3/1106-preview ☁️ | 60 | 75 | 98 | 52 | 88 | 62 | 72 | 2.52 € | 0.68 rps |
| GPT-3.5 v2/0613 ☁️ | 62 | 79 | 73 | 75 | 81 | 48 | 70 | 0.35 € | 1.39 rps |
| GPT-3.5 v3/1106 ☁️ | 62 | 68 | 71 | 63 | 78 | 59 | 67 | 0.24 € | 2.29 rps |
| GPT-3.5-instruct 0914 ☁️ | 44 | 90 | 69 | 60 | 88 | 32 | 64 | 0.36 € | 2.12 rps |
| Mistral 7B OpenChat-3.5 v3 0106 f16 ✅ | 56 | 86 | 67 | 52 | 88 | 26 | 62 | 0.37 € | 2.99 rps |
| GPT-3.5 v1/0301 ☁️ | 44 | 75 | 67 | 67 | 82 | 24 | 60 | 0.36 € | 3.93 rps |
| Mistral 7B OpenChat-3.5 v1 f16 ✅ | 46 | 72 | 72 | 49 | 88 | 31 | 60 | 0.51 € | 2.14 rps |
| Starling 7B-alpha f16 ⚠️ | 51 | 66 | 67 | 45 | 88 | 36 | 59 | 0.61 € | 1.80 rps |
| Mistral 7B OpenChat-3.5 v2 1210 f16 ✅ | 51 | 74 | 72 | 41 | 75 | 31 | 57 | 0.36 € | 3.05 rps |
| Mistral 7B OpenOrca f16 ☁️ | 42 | 57 | 76 | 21 | 78 | 26 | 50 | 0.43 € | 2.55 rps |
| Mistral 7B Instruct v0.1 f16 ☁️ | 31 | 70 | 61 | 44 | 62 | 21 | 48 | 0.79 € | 1.39 rps |
| Llama2 13B Vicuna-1.5 f16🦙 | 36 | 37 | 44 | 39 | 82 | 38 | 46 | 1.02 € | 1.07 rps |
| Llama2 13B Hermes f16🦙 | 38 | 23 | 30 | 61 | 60 | 43 | 42 | 1.03 € | 1.06 rps |
| Llama2 13B Hermes b8🦙 | 32 | 24 | 29 | 61 | 60 | 43 | 42 | 4.94 € | 0.22 rps |
| Llama2 13B Puffin f16🦙 | 37 | 12 | 33 | 33 | 56 | 41 | 36 | 4.89 € | 0.22 rps |
| Llama2 13B Puffin b8🦙 | 37 | 9 | 34 | 31 | 56 | 39 | 34 | 8.65 € | 0.13 rps |
| Llama2 13B chat f16🦙 | 15 | 38 | 17 | 30 | 75 | 8 | 30 | 0.76 € | 1.43 rps |
| Llama2 13B chat b8🦙 | 15 | 38 | 15 | 30 | 75 | 6 | 30 | 3.35 € | 0.33 rps |
| Orca 2 13B f16 ⚠️ | 15 | 22 | 32 | 22 | 67 | 19 | 29 | 0.99 € | 1.11 rps |
| Llama2 7B chat f16🦙 | 20 | 33 | 14 | 27 | 50 | 20 | 27 | 0.59 € | 1.86 rps |
| Mistral 7B Zephyr-β f16 ✅ | 23 | 34 | 27 | 44 | 29 | 4 | 27 | 0.51 € | 2.14 rps |
| Mistral 7B Notus-v1 f16 ⚠️ | 16 | 43 | 6 | 41 | 48 | 4 | 26 | 0.80 € | 1.37 rps |
| Mistral 7B Instruct v0.2 f16 ☁️ | 7 | 21 | 34 | 13 | 58 | 8 | 24 | 1.00 € | 1.10 rps |
| Mistral 7B f16 ☁️ | 0 | 4 | 20 | 42 | 52 | 12 | 22 | 0.93 € | 1.17 rps |
| Orca 2 7B f16 ⚠️ | 13 | 0 | 22 | 18 | 52 | 4 | 18 | 0.81 € | 1.34 rps |
| Llama2 7B f16🦙 | 0 | 2 | 5 | 2 | 28 | 2 | 7 | 1.01 € | 1.08 rps |
The benchmark categories in detail
Here's exactly what we're looking at with the different categories of LLM Leaderboards
-
How well can the model work with large documents and knowledge bases?
-
How well does the model support work with product catalogs and marketplaces?
-
Can the model easily interact with external APIs, services and plugins?
-
How well can the model support marketing activities, e.g. brainstorming, idea generation and text generation?
-
How well can the model reason and draw conclusions in a given context?
-
Can the model generate code and help with programming?
-
The estimated cost of running the workload. For cloud-based models, we calculate the cost according to the pricing. For on-premises models, we estimate the cost based on GPU requirements for each model, GPU rental cost, model speed, and operational overhead.
-
The "Speed" column indicates the estimated speed of the model in requests per second (without batching). The higher the speed, the better.
Mistral 7B OpenChat v3 (0106) beats ChatGPT-3.5
Open source models are getting better and better with each passing month. This is great news as you can run these models locally on your machines. Our customers really appreciate this option!
→ Progress with open source models: More and more local versions possible
→ Mistral 7B OpenChat-3.5: A top contender among the open source models
Among these open source models, one of the best candidates is a fine-tune version of Mistral 7B, called Mistral 7B OpenChat-3.5, which offers a very good balance between quality, performance and the computing resources required to run it locally on your own hardware.
→ Superiority of the third version: Mistral 7B OpenChat-3.5 outperforms ChatGPT-3.5 in business tasks
Up to this point, we have mainly used the first version of Mistral 7B OpenChat-3.5 (fine-tune). However, our latest benchmarks show that the third version is much better. It even beats ChatGPT-3.5 on our business-oriented tasks!

Nevertheless, there is still a long way to go, as the version of ChatGPT-3.5 that was surpassed by Mistral 7B OpenChat-3.5 is the oldest and weakest. Nevertheless, this is a start and we are very excited to see what awaits us in the coming weeks and months.
Why are there no benchmarks for Mixtral 8x7B or Mistral-Medium?
You have probably heard of another, much more powerful version of Mistral: Mixtral 8x7B. This model uses a different architecture called sparse mixture of experts (MoE).
This MoE model is more powerful than Mistral 7B. It also drives the hosted model mistral-small from MistralAI to. We do not have any of these models in this LLM benchmark. Nor do we have the Mistral Medium model, which is even more powerful than the Mixtral 8X7B.
The reason why we have not yet included them in the benchmarks
The second generation of Mistral models have been trained to perform better than the first generation. These models provide better answers, but sometimes fail to follow the answer format exactly as instructed in the prompt and the Few-Shot examples. They are more detailed than necessary.
This comprehensiveness makes the model less useful for business-oriented tasks and the automation of business processes.
Of course, you can add post-processing when using the model to remove additional explanations. However, it would be unfair to the other models to add mistral-specific post-processing to the Trustbit LLM benchmarks, so we will not do this.
Trustbit's benchmarks helped Mistral's AI team to better understand issues with the model
We reported the issue to the Mistral AI teams and provided reproducible examples. The Trustbit LLM benchmarks helped to understand the impact and narrow down the scope: The first generation of models did not have the issue.
The Mistral AI team is making rapid progress and is already working on the problem:
"Our models sometimes just tend to be excessive... Our team is also working on it and will improve it."
Benchmark update after fixing the problem
At this time, we have decided not to include the current mistral-tiny/mistral-small/mistral-medium benchmark results as this is only a temporary issue that will be resolved soon. As soon as this happens, we will publish an update on the benchmarks.
Planning synthetic benchmarks: wizards, Q&A and RAGs
Although raw LLM benchmarks are interesting and exciting, they can sometimes be too technical and not particularly relevant.
As we've learned with our customers, the performance of an LLM is just one of many factors that contribute to the value a complete product or service can provide. At this time, we are considering creating another synthetic benchmark - one to evaluate the performance of complete AI systems on business-specific tasks.
For example:
find the correct answer in a large PDF
Synthesize a correct answer that requires looking up multiple documents
Correctly evaluate and process incoming documentation
Your opinion is needed: Which business-specific tasks should we benchmark?
Are there other business-specific tasks that you would like to see in our benchmark market? We look forward to your input and would be delighted to hear from you!
You are also welcome to contact us to get an insight into such a benchmark before it is published.
Trustbit LLM Benchmarks Archive

Interested in the benchmarks of the past months? You can find all the links on our LLM Benchmarks overview page!