Benchmarks for ChatGPT and Co
March 2024

The highlights of the month:
Anthropic Claude 3 models - Great performance jump and more capabilities
Claude 3 Haiku - great model for working with corporate documents on a large scale
Gemini Pro 1.0 - good model, but there are better alternatives
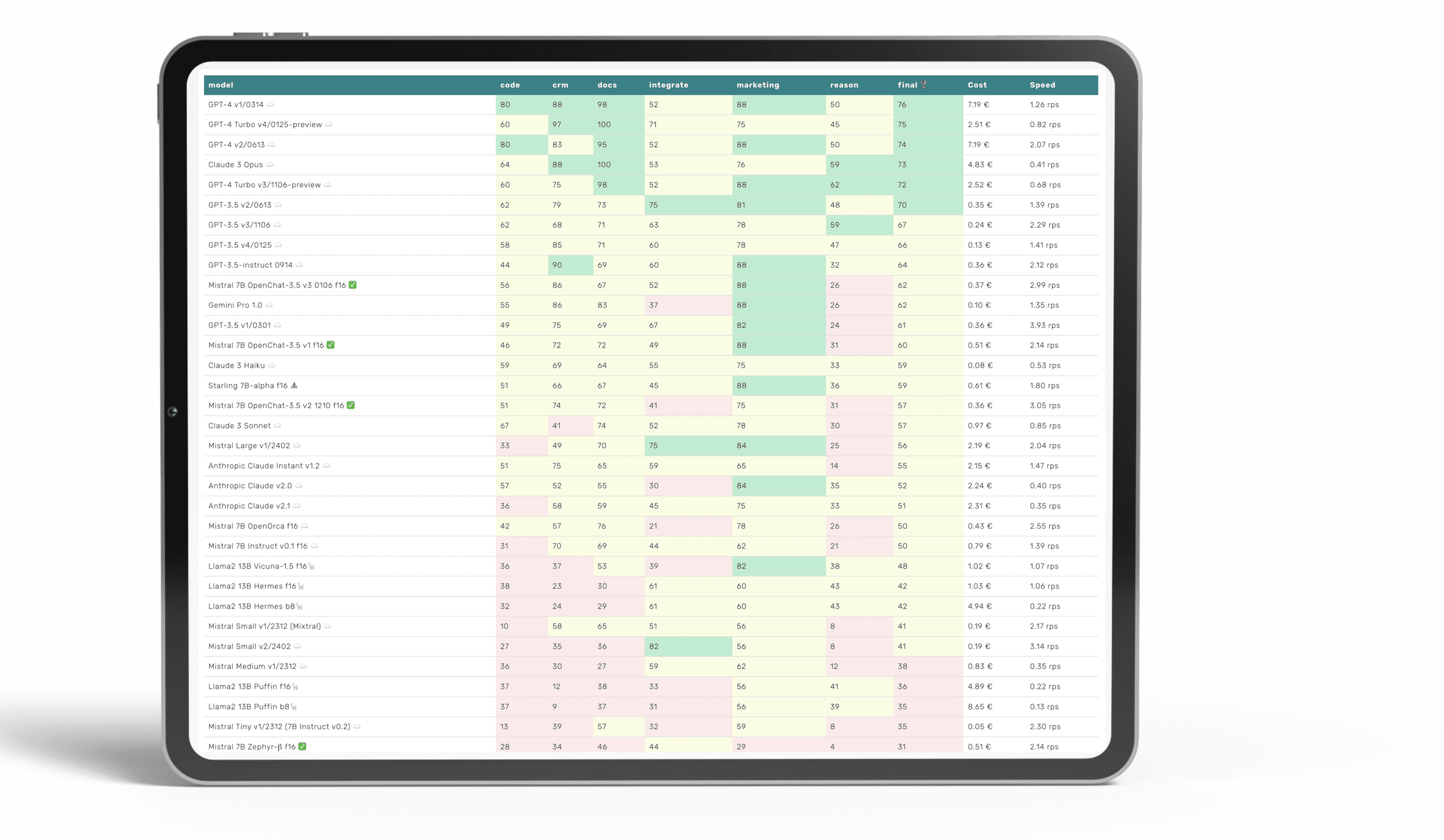
LLM Benchmarks | March 2024
The Trustbit benchmarks evaluate the models in terms of their suitability for digital product development. The higher the score, the better.
☁️ - Cloud models with proprietary license
✅ - Open source models that can be run locally without restrictions
🦙 - Local models with Llama license
| model | code | crm | docs | integrate | marketing | reason | final 🏆 | Cost | Speed |
|---|---|---|---|---|---|---|---|---|---|
| GPT-4 v1/0314 ☁️ | 80 | 88 | 98 | 52 | 88 | 50 | 76 | 7.19 € | 1.26 rps |
| GPT-4 Turbo v4/0125-preview ☁️ | 60 | 97 | 100 | 71 | 75 | 45 | 75 | 2.51 € | 0.82 rps |
| GPT-4 v2/0613 ☁️ | 80 | 83 | 95 | 52 | 88 | 50 | 74 | 7.19 € | 2.07 rps |
| Claude 3 Opus ☁️ | 64 | 88 | 100 | 53 | 76 | 59 | 73 | 4.83 € | 0.41 rps |
| GPT-4 Turbo v3/1106-preview ☁️ | 60 | 75 | 98 | 52 | 88 | 62 | 72 | 2.52 € | 0.68 rps |
| GPT-3.5 v2/0613 ☁️ | 62 | 79 | 73 | 75 | 81 | 48 | 70 | 0.35 € | 1.39 rps |
| GPT-3.5 v3/1106 ☁️ | 62 | 68 | 71 | 63 | 78 | 59 | 67 | 0.24 € | 2.29 rps |
| GPT-3.5 v4/0125 ☁️ | 58 | 85 | 71 | 60 | 78 | 47 | 66 | 0.13 € | 1.41 rps |
| GPT-3.5-instruct 0914 ☁️ | 44 | 90 | 69 | 60 | 88 | 32 | 64 | 0.36 € | 2.12 rps |
| Mistral 7B OpenChat-3.5 v3 0106 f16 ✅ | 56 | 86 | 67 | 52 | 88 | 26 | 62 | 0.37 € | 2.99 rps |
| Gemini Pro 1.0 ☁️ | 55 | 86 | 83 | 37 | 88 | 26 | 62 | 0.10 € | 1.35 rps |
| GPT-3.5 v1/0301 ☁️ | 49 | 75 | 69 | 67 | 82 | 24 | 61 | 0.36 € | 3.93 rps |
| Mistral 7B OpenChat-3.5 v1 f16 ✅ | 46 | 72 | 72 | 49 | 88 | 31 | 60 | 0.51 € | 2.14 rps |
| Claude 3 Haiku ☁️ | 59 | 69 | 64 | 55 | 75 | 33 | 59 | 0.08 € | 0.53 rps |
| Starling 7B-alpha f16 ⚠️ | 51 | 66 | 67 | 45 | 88 | 36 | 59 | 0.61 € | 1.80 rps |
| Mistral 7B OpenChat-3.5 v2 1210 f16 ✅ | 51 | 74 | 72 | 41 | 75 | 31 | 57 | 0.36 € | 3.05 rps |
| Claude 3 Sonnet ☁️ | 67 | 41 | 74 | 52 | 78 | 30 | 57 | 0.97 € | 0.85 rps |
| Mistral Large v1/2402 ☁️ | 33 | 49 | 70 | 75 | 84 | 25 | 56 | 2.19 € | 2.04 rps |
| Anthropic Claude Instant v1.2 ☁️ | 51 | 75 | 65 | 59 | 65 | 14 | 55 | 2.15 € | 1.47 rps |
| Anthropic Claude v2.0 ☁️ | 57 | 52 | 55 | 30 | 84 | 35 | 52 | 2.24 € | 0.40 rps |
| Anthropic Claude v2.1 ☁️ | 36 | 58 | 59 | 45 | 75 | 33 | 51 | 2.31 € | 0.35 rps |
| Mistral 7B OpenOrca f16 ☁️ | 42 | 57 | 76 | 21 | 78 | 26 | 50 | 0.43 € | 2.55 rps |
| Mistral 7B Instruct v0.1 f16 ☁️ | 31 | 70 | 69 | 44 | 62 | 21 | 50 | 0.79 € | 1.39 rps |
| Llama2 13B Vicuna-1.5 f16🦙 | 36 | 37 | 53 | 39 | 82 | 38 | 48 | 1.02 € | 1.07 rps |
| Llama2 13B Hermes f16🦙 | 38 | 23 | 30 | 61 | 60 | 43 | 42 | 1.03 € | 1.06 rps |
| Llama2 13B Hermes b8🦙 | 32 | 24 | 29 | 61 | 60 | 43 | 42 | 4.94 € | 0.22 rps |
| Mistral Small v1/2312 (Mixtral) ☁️ | 10 | 58 | 65 | 51 | 56 | 8 | 41 | 0.19 € | 2.17 rps |
| Mistral Small v2/2402 ☁️ | 27 | 35 | 36 | 82 | 56 | 8 | 41 | 0.19 € | 3.14 rps |
| Mistral Medium v1/2312 ☁️ | 36 | 30 | 27 | 59 | 62 | 12 | 38 | 0.83 € | 0.35 rps |
| Llama2 13B Puffin f16🦙 | 37 | 12 | 38 | 33 | 56 | 41 | 36 | 4.89 € | 0.22 rps |
| Llama2 13B Puffin b8🦙 | 37 | 9 | 37 | 31 | 56 | 39 | 35 | 8.65 € | 0.13 rps |
| Mistral Tiny v1/2312 (7B Instruct v0.2) ☁️ | 13 | 39 | 57 | 32 | 59 | 8 | 35 | 0.05 € | 2.30 rps |
| Mistral 7B Zephyr-β f16 ✅ | 28 | 34 | 46 | 44 | 29 | 4 | 31 | 0.51 € | 2.14 rps |
| Llama2 13B chat f16🦙 | 15 | 38 | 17 | 30 | 75 | 8 | 30 | 0.76 € | 1.43 rps |
| Llama2 13B chat b8🦙 | 15 | 38 | 15 | 30 | 75 | 6 | 30 | 3.35 € | 0.33 rps |
| Mistral 7B Notus-v1 f16 ⚠️ | 16 | 43 | 25 | 41 | 48 | 4 | 30 | 0.80 € | 1.37 rps |
| Orca 2 13B f16 ⚠️ | 15 | 22 | 32 | 22 | 67 | 19 | 29 | 0.99 € | 1.11 rps |
| Llama2 7B chat f16🦙 | 20 | 33 | 20 | 27 | 50 | 20 | 28 | 0.59 € | 1.86 rps |
| Mistral 7B Instruct v0.2 f16 ☁️ | 7 | 21 | 50 | 13 | 58 | 8 | 26 | 1.00 € | 1.10 rps |
| Mistral 7B f16 ☁️ | 0 | 4 | 42 | 42 | 52 | 12 | 25 | 0.93 € | 1.17 rps |
| Orca 2 7B f16 ⚠️ | 13 | 0 | 24 | 18 | 52 | 4 | 19 | 0.81 € | 1.34 rps |
| Llama2 7B f16🦙 | 0 | 2 | 18 | 2 | 28 | 2 | 9 | 1.01 € | 1.08 rps |
The benchmark categories in detail
Here's exactly what we're looking at with the different categories of LLM Leaderboards
-
How well can the model work with large documents and knowledge bases?
-
How well does the model support work with product catalogs and marketplaces?
-
Can the model easily interact with external APIs, services and plugins?
-
How well can the model support marketing activities, e.g. brainstorming, idea generation and text generation?
-
How well can the model reason and draw conclusions in a given context?
-
Can the model generate code and help with programming?
-
The estimated cost of running the workload. For cloud-based models, we calculate the cost according to the pricing. For on-premises models, we estimate the cost based on GPU requirements for each model, GPU rental cost, model speed, and operational overhead.
-
The "Speed" column indicates the estimated speed of the model in requests per second (without batching). The higher the speed, the better.
Anthropic Claude 3 models
Anthropic recently released the third generation of its models:
Haiku
Sonnet
Opus
All models show huge improvements compared to the previous versions in our product-oriented LLM benchmarks.
It looks like Anthropic has finally started listening to the clients that use Large Language Models to build real products for the businesses and enterprise.

Claude 3 Opus overtakes GPT-4 models
Claude 3 Opus has made the biggest leap forward and has caught up with the GPT-4 models.
In the "Documents" category, Opus achieved a perfect score of 100, which means that it can perform very well on tasks that involve reading documents, extracting and transforming information. These tasks are used extensively in our products and prototypes that use Domain-Driven Design and Knowledge Maps to work with complex business domains.
💡 These news are great for our clients, and not so great for us, since we now have to rework the entire benchmark to add even more challenging edge cases into the “Docs” category.
Claude 3 Sonnet: The mid-range model
Claude 3 Sonnet is the middle-range model. It has also improved over Claude 2 models, although the jump is not so substantial al the first glance.
Improvements and cost reduction
However the cost of running the model has dropped more than 2x, which implies substantial improvements under the hood.
Another important aspect: all the models in Claude 3 range claim better multilingual support (which is important for international companies), and huge context of 200K tokens. These are big improvements worth celebrating!
Claude 3 Haiku
Claude 3 Haiku from Anthropic deserves special praise. It is the smallest model that even managed to outperform Claude 3 Sonnet in our benchmarks.
Focus on "enterprise workloads"
Anthropic mentions "enterprise workloads" several times when talking about this model. Perhaps this focus was the key to performing so well in such tasks.
The model itself isn’t as good on our benchmarks as their PR mentions, though. It outperforms neither GPT-3.5 nor Gemini Pro. However, that is not the point. Given its huge context window of 200k and nice pricing model of 1:5 (input tokens cost 5x less than output tokens), it may be the default model for working with large enterprise documents at low cost.
The model itself is 12x cheaper than Claude 3 Sonnet and 60x cheaper than Claude 3 Opus.
Gemini Pro 1.0 - comparable to Claude 3 Haiku
Gemini Pro 1.0 is a new mid-range model from Google. The entire product line includes Nano, Pro and Ultra.
This model beats the first version of GPT-3.5 (which was released almost a year ago) and performs at the level of good Mistral 7B fine tunes in our tasks.
The model is also quite affordable, roughly comparable to Claude 3 Haiku.
However, typical for Google, integration with Gemini Pro 1.0 is a little more difficult, especially if you are operating within the EU. The context size is also smaller.
If you have the choice, we recommend using GPT-3.5 (v4/0125), Claude 3 Haiku or even a good fine-tune from Mistral 7B locally with vLLM.
Table Comprehension Challenge
Here is an example of a benchmark for the Enterprise AI Benchmarks suite. It no longer tests just a text manipulation, but a more complex task.
For example, you have a PDF document with technical specifications for LEDs. You want an answer for the following question: What is the typical peak forward voltage for GL538?
As you can see below, the number is right there:

If you upload the PDF to an AI system of your choice, the system will fail to provide a correct answer. Even ChatGPT-4 with Vision will not be able to accomplish this task.

Try it out for yourself!
You can test it yourself by downloading the PDF here and uploading it to an AI system of your choice.
The document poses a challenge for AI systems for two reasons:
There is no text layer in this PDF, only the image
The table itself has gaps and is irregular
While in reality, enterprise documents can be in even worse conditions (not to mention ☕️ coffee stains on incoming scans), the current configuration already makes it very difficult for LLM-driven systems to read the document.
What could a good AI-driven system do in this case?
Isolate the relevant product page
Select the relevant table on the product page
Perform the understanding of the table on the selected table
This makes the task feasible for GPT-4 Vision.

Outlook for upcoming benchmarks
This is one of the tasks that will be featured in the upcoming AI Enterprise Benchmarks. Tables and spreadsheets are the essence of business processes, and all good LLM-powered assistants need to understand them to be useful. We'll find out which models are particularly good at this!

Trustbit LLM Benchmarks Archive
Interested in the benchmarks of the past months? You can find all the links on our LLM Benchmarks overview page!