State of Fast Feedback in Data Science Projects
Let’s talk about the productivity in Data Science and Machine Learning projects (DSML)
DSML projects can be quite different from the software projects: a lot of R&D in a rapidly evolving landscape, working with data, distributions and probabilities instead of code. However, there is one thing in common: iterative development process matters a lot.
For example in software engineering, rapid iterations help a lot in debugging complex issues or working towards a tricky issue. In product development, an ability to rapidly roll out new version can be a deal-breaker for achieving customer satisfaction. Paul Graham eloquently covers that in his “Beating the averages” essay.
Likewise, in Data Science and Machine Learning projects, iterations help data scientists to rapidly test their theories and converge towards the solution that will create value. If we assume that 87% of data science projects fail (which looks about right to me), then having a fast feedback loop could help to get to the successful 13% faster.
Yet, there is a problem in the industry with that.
Let use a basic data science pipeline as an example. It will have a predefined structure to make it easier for collaboration between different teams in the department.
There will be the following steps:
Initialise the pipeline run, deriving any per-run variables from the initial config
Load and prepare the training data
Perform model training
Evaluate the model on a separate dataset
Prepare the model for the use
Run batch prediction against the resulting model
The de facto language for the pipelines in Python. We can provide a minimal implementation in a console application and run it locally. On my laptop it takes ~0.3-0.5 sec.
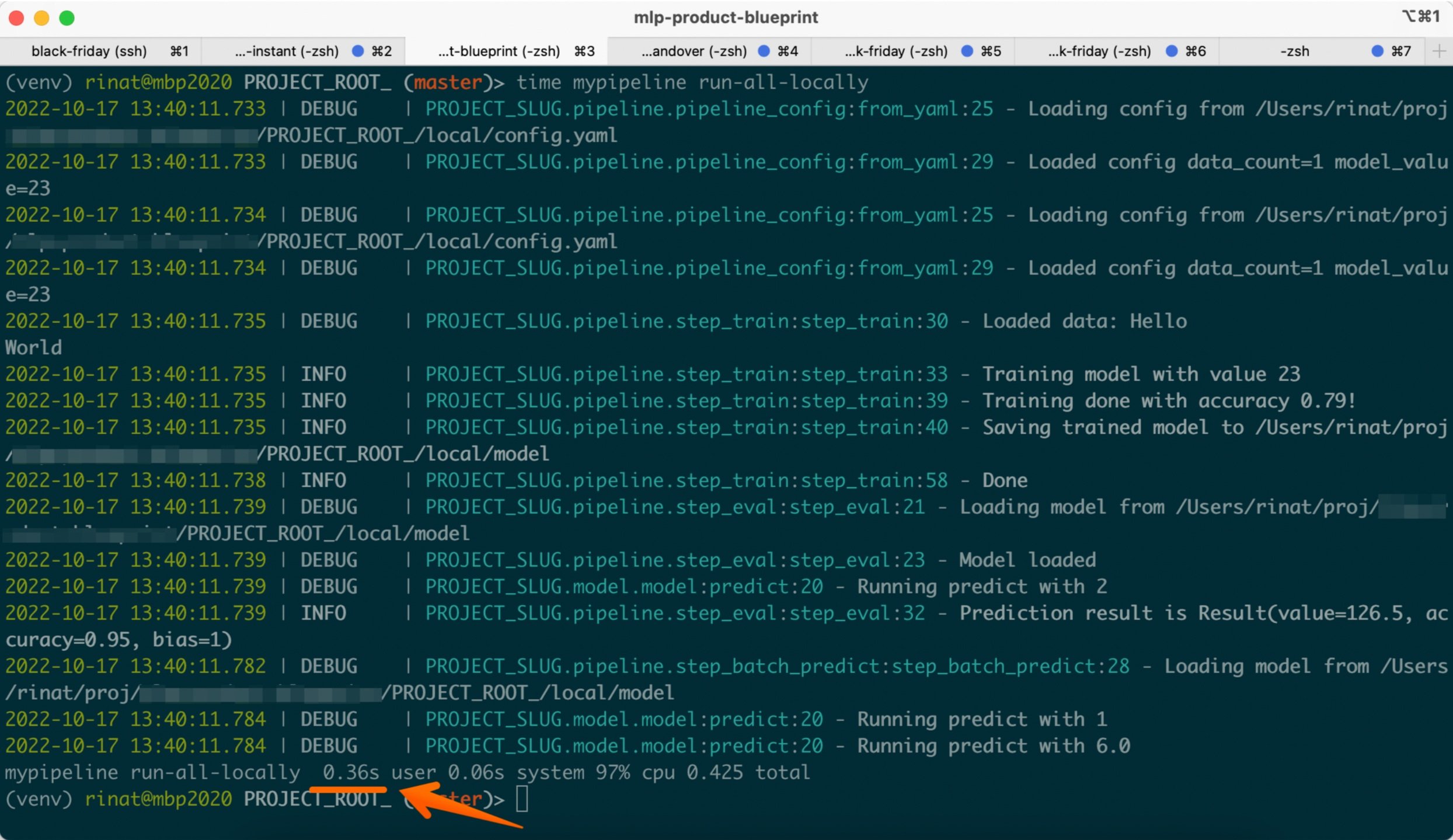
That is good enough.
If the computation overhead of a real pipeline is 5 minutes, then we could run up to 12 iterations in an hour.
However, the industry way to run these pipelines is via Kubeflow (ML toolkit for Kubernetes). Google Vertex is one of the most stable implementations.
If we map our pipeline components to a Kubeflow pipeline, we’ll get something like that:

How many experiments per our can we run here?
At this point, the computation overhead doesn’t even matter. Since it takes 33 minutes per run, we could run only up to experiment per hour.
The execution takes 5000x more time on Vertex than it takes on a local machine. Although that time is a paid compute time, the biggest hit is not a financial one, but more of a productivity loss.
And that is the most frustrating problem with the state of the data science pipelines today. Major hosting players make more money from less efficient data science pipelines. This might reduce incentives to prioritize performance-improving changes. This in turn negatively impacts the ability of small data science teams to have fast feedback loops and innovate efficiently.