Trustbit LLM Leaderboard
“How can we run ChatGPT on our servers?”, “Which GPT Model is the best?” - have you ever wondered about this?
While helping our customers to integrate Large Language Models into business processes, we heard these questions frequently enough. To address them in a pragmatic way, we have created our own LLM Product Leaderboard.
This leaderboard is similar to the famous leaderboards from LMSYS.org and HuggingFace Open LLM Leaderboard. There is only one important distinction: Trustbit LLM leaderboard focuses on building and shipping products.
Scores are based on the benchmarks that were extracted from software products that we’ve build. They rank capability of any given LLM to carry out specific tasks in making a product work.
Scores rank each model from 0 to 100 in the following categories:
docs - working with large documents and knowledge bases
crm - capabilities for working with product catalogues and marketplaces
integrate - ability to interact with external APIs, services, and plugins
marketing - assistance in marketing activities: brainstorming, idea refinement, text generation
reason - ability to reason within the provided context
code - code generation and reasoning
The final rating aggregates these scores and provides a global rank for a given LLM model.
Here is the Trustbit LLM Leaderboard for June 2023:
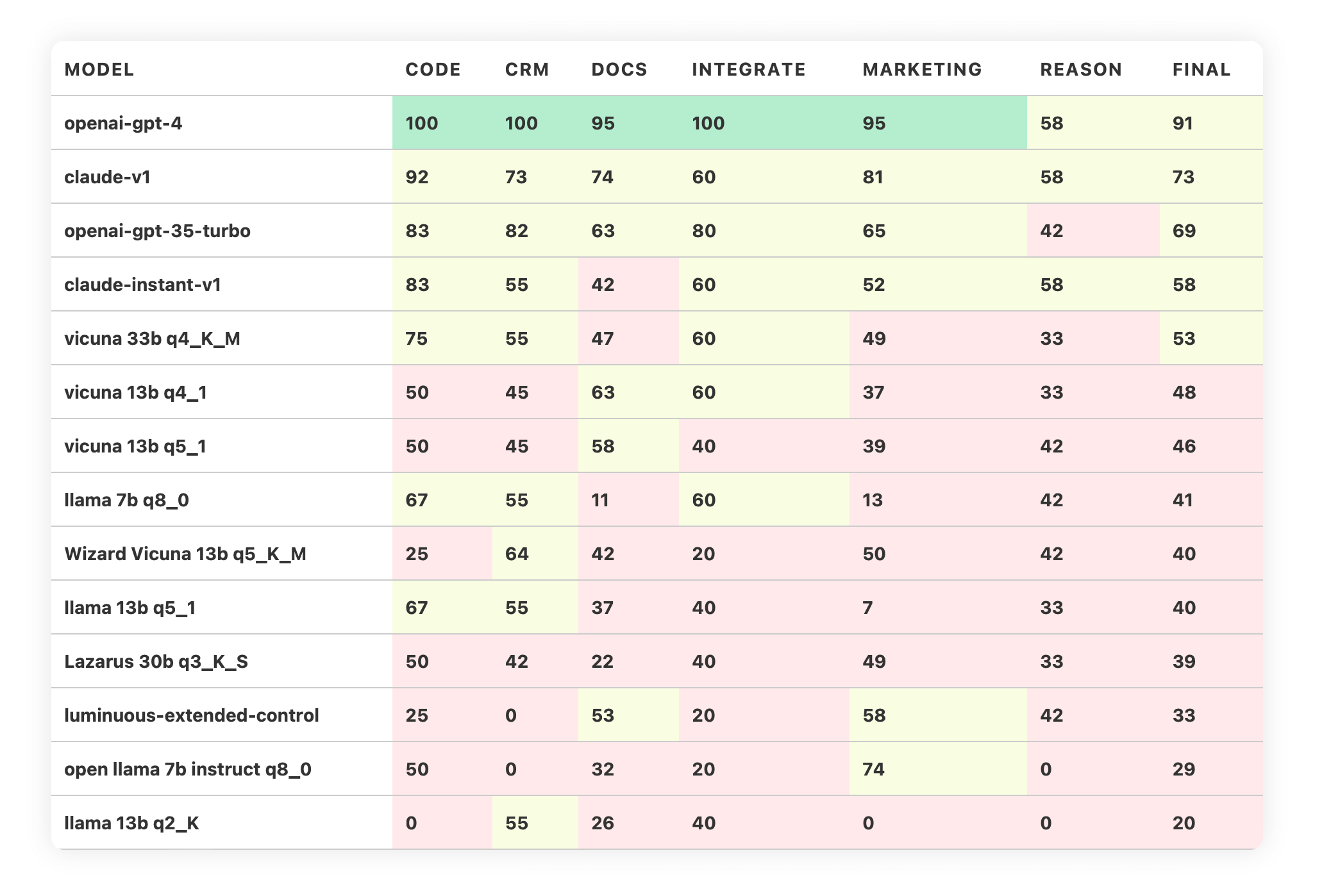
Chat GPT-4 is the best
Chat GPT-4 is still the uncontested champion. This is the model that we are using in early stages of product development, to establish baseline and prove that the concept works.
We suggest our customers to use Azure OpenAI deployment whenever possible.
Anthropic Claude is a good backup
Importance of OpenAI alternatives are hard to overstate. OpenAI itself is GPU-constrained. We also had reports of Azure OpenAI replying like these to customers applying for the access to GPT-4:
Please note that we are currently paused on onboarding new GPT-4 customers due to the high demand and do not have an estimated time for when we will onboard new customers.
Claude model from Anthropic holds a strong second place in our leaderboard, ranking between GPT-4 and GPT-3.5. Some of our peers report that they even prefer working with Claude over GPT-4.
Open models get surprisingly good
Open models get surprisingly good results.
Trustbit LLM Leaderboard includes only the most popular small models, largest one being Vicuna 33B (v1.1 with q4_K_M quantisation). You can download these models and run them within the data centre, or even locally on a laptop.
Vicuna 33B is currently the best model within the leaderboard. However, the new Falcon and MPT models have a chance of ranking even higher.
GPT-4 is rumoured to run as a mixture of 8 experts working together in an ensemble. What if we picked the best open model in each category, joining them in a single “open ensemble” model?
The resulting model would take a confident fourth place in the leaderboard, outrunning Claude instant.
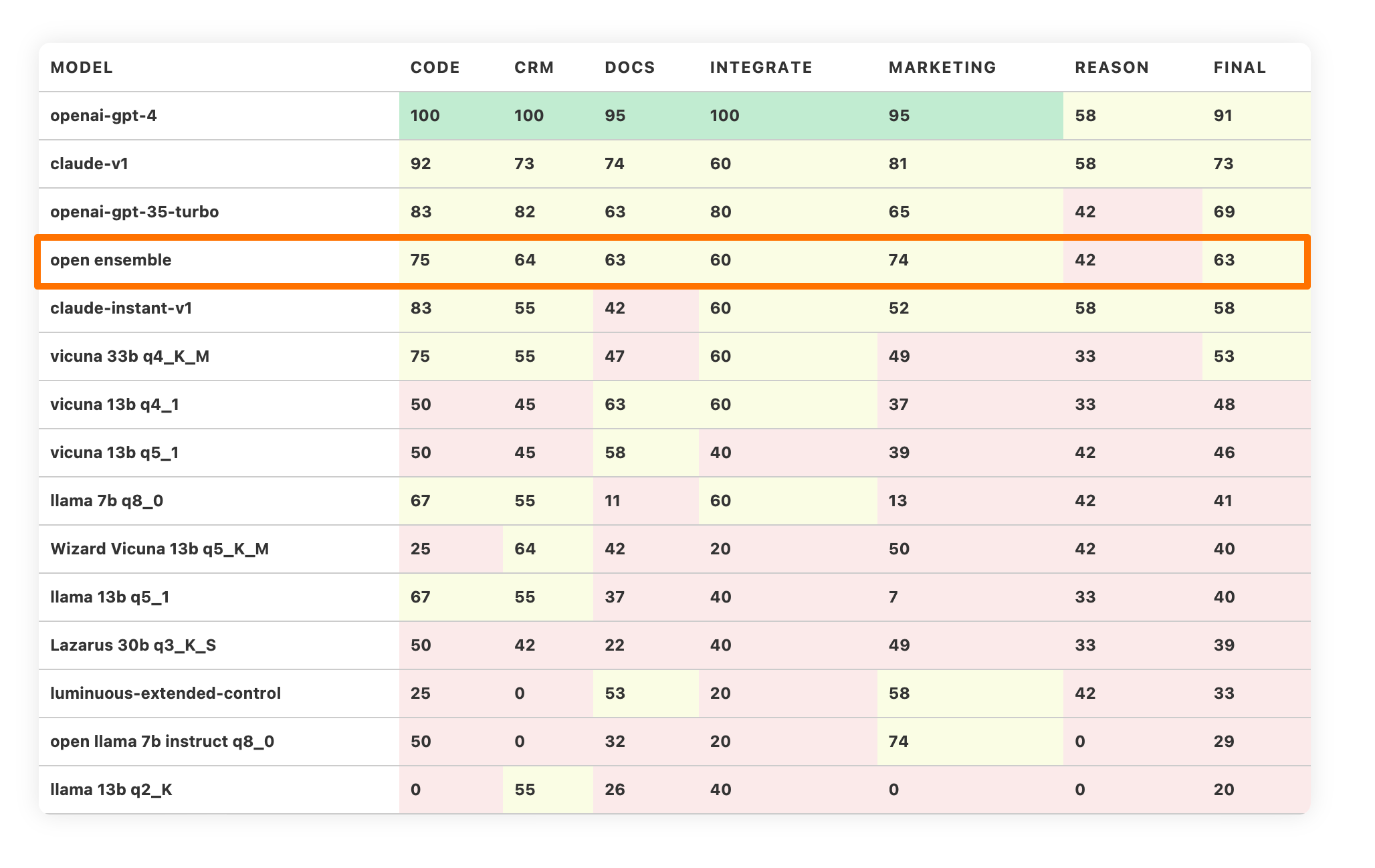
We expect “open ensemble” model to get even better results, as we add new large models into this leaderboard.
AlephAlpha Luminous Extended scores low
Luminous Extended from Aleph Alpha scored quite low in the competition, even below the compressed variants of LLaMa 13B and Vicuna 13B.
It looks like the EU model still has a long way to go.
Note, that this report doesn't include the best model from Aleph Alpha - “Luminous Supreme”, which has a chance of scoring higher.
New Leaderboard Versions
This is the very first public LLM Leaderboard report from Trustbit.
Stay tuned for further updates! They will include:
Larger open models (we are especially interested in MPT, Falcon and OpenLLaMA)
Multi-language scores
Refined benchmarks, as we extract them from the new products.