Benchmarks für ChatGPT und Co
März 2024

Die Highlights des Monats:
Anthropic Claude 3 Modelle - Großer Leistungssprung und mehr Fähigkeiten
Claude 3 Haiku - großartiges Modell für die Arbeit mit Unternehmensdokumenten in großem Umfang
Gemini Pro 1.0 - gutes Modell, aber es gibt bessere Alternativen
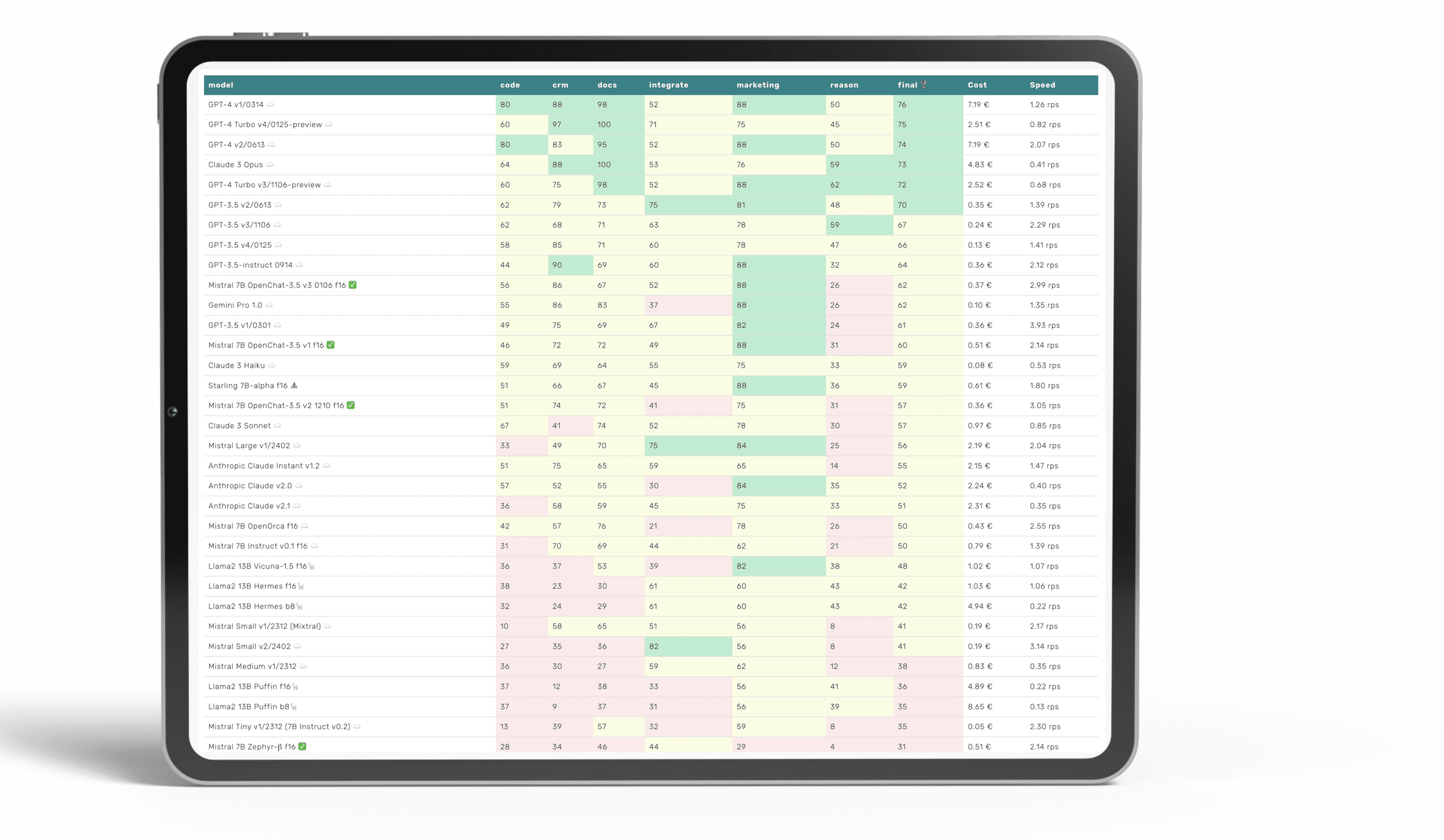
LLM Benchmarks | März 2024
Die Trustbit-Benchmarks bewerten die Modelle in Bezug auf ihre Eignung für die digitale Produktentwicklung. Je höher die Punktezahl, desto besser.
☁️ - Cloud-Modelle mit proprietärer Lizenz
✅ - Open-Source-Modelle, die lokal ohne Einschränkungen ausgeführt werden können
🦙 - Lokale Modelle mit Llama2-Lizenz
| model | code | crm | docs | integrate | marketing | reason | final 🏆 | Cost | Speed |
|---|---|---|---|---|---|---|---|---|---|
| GPT-4 v1/0314 ☁️ | 80 | 88 | 98 | 52 | 88 | 50 | 76 | 7.19 € | 1.26 rps |
| GPT-4 Turbo v4/0125-preview ☁️ | 60 | 97 | 100 | 71 | 75 | 45 | 75 | 2.51 € | 0.82 rps |
| GPT-4 v2/0613 ☁️ | 80 | 83 | 95 | 52 | 88 | 50 | 74 | 7.19 € | 2.07 rps |
| Claude 3 Opus ☁️ | 64 | 88 | 100 | 53 | 76 | 59 | 73 | 4.83 € | 0.41 rps |
| GPT-4 Turbo v3/1106-preview ☁️ | 60 | 75 | 98 | 52 | 88 | 62 | 72 | 2.52 € | 0.68 rps |
| GPT-3.5 v2/0613 ☁️ | 62 | 79 | 73 | 75 | 81 | 48 | 70 | 0.35 € | 1.39 rps |
| GPT-3.5 v3/1106 ☁️ | 62 | 68 | 71 | 63 | 78 | 59 | 67 | 0.24 € | 2.29 rps |
| GPT-3.5 v4/0125 ☁️ | 58 | 85 | 71 | 60 | 78 | 47 | 66 | 0.13 € | 1.41 rps |
| GPT-3.5-instruct 0914 ☁️ | 44 | 90 | 69 | 60 | 88 | 32 | 64 | 0.36 € | 2.12 rps |
| Mistral 7B OpenChat-3.5 v3 0106 f16 ✅ | 56 | 86 | 67 | 52 | 88 | 26 | 62 | 0.37 € | 2.99 rps |
| Gemini Pro 1.0 ☁️ | 55 | 86 | 83 | 37 | 88 | 26 | 62 | 0.10 € | 1.35 rps |
| GPT-3.5 v1/0301 ☁️ | 49 | 75 | 69 | 67 | 82 | 24 | 61 | 0.36 € | 3.93 rps |
| Mistral 7B OpenChat-3.5 v1 f16 ✅ | 46 | 72 | 72 | 49 | 88 | 31 | 60 | 0.51 € | 2.14 rps |
| Claude 3 Haiku ☁️ | 59 | 69 | 64 | 55 | 75 | 33 | 59 | 0.08 € | 0.53 rps |
| Starling 7B-alpha f16 ⚠️ | 51 | 66 | 67 | 45 | 88 | 36 | 59 | 0.61 € | 1.80 rps |
| Mistral 7B OpenChat-3.5 v2 1210 f16 ✅ | 51 | 74 | 72 | 41 | 75 | 31 | 57 | 0.36 € | 3.05 rps |
| Claude 3 Sonnet ☁️ | 67 | 41 | 74 | 52 | 78 | 30 | 57 | 0.97 € | 0.85 rps |
| Mistral Large v1/2402 ☁️ | 33 | 49 | 70 | 75 | 84 | 25 | 56 | 2.19 € | 2.04 rps |
| Anthropic Claude Instant v1.2 ☁️ | 51 | 75 | 65 | 59 | 65 | 14 | 55 | 2.15 € | 1.47 rps |
| Anthropic Claude v2.0 ☁️ | 57 | 52 | 55 | 30 | 84 | 35 | 52 | 2.24 € | 0.40 rps |
| Anthropic Claude v2.1 ☁️ | 36 | 58 | 59 | 45 | 75 | 33 | 51 | 2.31 € | 0.35 rps |
| Mistral 7B OpenOrca f16 ☁️ | 42 | 57 | 76 | 21 | 78 | 26 | 50 | 0.43 € | 2.55 rps |
| Mistral 7B Instruct v0.1 f16 ☁️ | 31 | 70 | 69 | 44 | 62 | 21 | 50 | 0.79 € | 1.39 rps |
| Llama2 13B Vicuna-1.5 f16🦙 | 36 | 37 | 53 | 39 | 82 | 38 | 48 | 1.02 € | 1.07 rps |
| Llama2 13B Hermes f16🦙 | 38 | 23 | 30 | 61 | 60 | 43 | 42 | 1.03 € | 1.06 rps |
| Llama2 13B Hermes b8🦙 | 32 | 24 | 29 | 61 | 60 | 43 | 42 | 4.94 € | 0.22 rps |
| Mistral Small v1/2312 (Mixtral) ☁️ | 10 | 58 | 65 | 51 | 56 | 8 | 41 | 0.19 € | 2.17 rps |
| Mistral Small v2/2402 ☁️ | 27 | 35 | 36 | 82 | 56 | 8 | 41 | 0.19 € | 3.14 rps |
| Mistral Medium v1/2312 ☁️ | 36 | 30 | 27 | 59 | 62 | 12 | 38 | 0.83 € | 0.35 rps |
| Llama2 13B Puffin f16🦙 | 37 | 12 | 38 | 33 | 56 | 41 | 36 | 4.89 € | 0.22 rps |
| Llama2 13B Puffin b8🦙 | 37 | 9 | 37 | 31 | 56 | 39 | 35 | 8.65 € | 0.13 rps |
| Mistral Tiny v1/2312 (7B Instruct v0.2) ☁️ | 13 | 39 | 57 | 32 | 59 | 8 | 35 | 0.05 € | 2.30 rps |
| Mistral 7B Zephyr-β f16 ✅ | 28 | 34 | 46 | 44 | 29 | 4 | 31 | 0.51 € | 2.14 rps |
| Llama2 13B chat f16🦙 | 15 | 38 | 17 | 30 | 75 | 8 | 30 | 0.76 € | 1.43 rps |
| Llama2 13B chat b8🦙 | 15 | 38 | 15 | 30 | 75 | 6 | 30 | 3.35 € | 0.33 rps |
| Mistral 7B Notus-v1 f16 ⚠️ | 16 | 43 | 25 | 41 | 48 | 4 | 30 | 0.80 € | 1.37 rps |
| Orca 2 13B f16 ⚠️ | 15 | 22 | 32 | 22 | 67 | 19 | 29 | 0.99 € | 1.11 rps |
| Llama2 7B chat f16🦙 | 20 | 33 | 20 | 27 | 50 | 20 | 28 | 0.59 € | 1.86 rps |
| Mistral 7B Instruct v0.2 f16 ☁️ | 7 | 21 | 50 | 13 | 58 | 8 | 26 | 1.00 € | 1.10 rps |
| Mistral 7B f16 ☁️ | 0 | 4 | 42 | 42 | 52 | 12 | 25 | 0.93 € | 1.17 rps |
| Orca 2 7B f16 ⚠️ | 13 | 0 | 24 | 18 | 52 | 4 | 19 | 0.81 € | 1.34 rps |
| Llama2 7B f16🦙 | 0 | 2 | 18 | 2 | 28 | 2 | 9 | 1.01 € | 1.08 rps |
Die Benchmark-Kategorien im Detail
Hier erfahren Sie, was wir mit den unterschiedlichen Kategorien der LLM Leaderboards genau untersuchen
-
Wie gut kann das Modell mit großen Dokumenten und Wissensdatenbanken arbeiten?
-
Wie gut unterstützt das Modell die Arbeit mit Produktkatalogen und Marktplätzen?
-
Kann das Modell problemlos mit externen APIs, Diensten und Plugins interagieren?
-
Wie gut kann das Modell bei Marketingaktivitäten unterstützen, z.B. beim Brainstorming, der Ideenfindung und der Textgenerierung?
-
Wie gut kann das Modell in einem gegebenen Kontext logisch denken und Schlussfolgerungen ziehen?
-
Kann das Modell Code generieren und bei der Programmierung helfen?
-
Die geschätzten Kosten für die Ausführung der Arbeitslast. Für cloud-basierte Modelle berechnen wir die Kosten gemäß der Preisgestaltung. Für lokale Modelle schätzen wir die Kosten auf Grundlage der GPU-Anforderungen für jedes Modell, der GPU-Mietkosten, der Modellgeschwindigkeit und des operationellen Overheads.
-
Die Spalte "Speed" gibt die geschätzte Geschwindigkeit des Modells in Anfragen pro Sekunde an (ohne Batching). Je höher die Geschwindigkeit, desto besser.
Anthropic Claude 3 Modelle
Anthropic hat kürzlich die dritte Generation ihrer Modelle veröffentlicht:
Haiku
Sonnet
Opus
Alle Modelle weisen enorme Verbesserungen gegenüber den vorherigen Versionen in unseren produktorientierten LLM-Benchmarks auf.
Es scheint, als hätte Anthropic endlich begonnen, auf die Kunden zu hören, die Sprachmodelle nutzen, um echte Produkte für Unternehmen zu entwickeln.

Claude 3 Opus überholt GPT-4-Modelle
Claude 3 Opus hat den größten Sprung nach vorne gemacht und hat die GPT-4-Modelle eingeholt.
In der Kategorie „Dokumente“ erreichte Opus die perfekte Punktzahl von 100, was bedeutet, dass es sehr gut bei Aufgaben funktionieren kann, die das Lesen von Dokumenten, das Extrahieren und Umwandeln von Informationen umfassen. Diese Aufgaben werden in unseren Produkten und Prototypen, die Domain-Driven Design und Knowledge Maps verwenden, um mit komplexen Geschäftsbereichen zu arbeiten, intensiv eingesetzt.
💡 Diese Nachrichten sind großartig für unsere Kunden, aber nicht so großartig für uns, da wir nun unsere gesamten Benchmarks überarbeiten müssen, um noch anspruchsvollere Edge-Cases in die Kategorie „Dokumente“ einzufügen.
Claude 3 Sonnet: Das Mittelklasse-Modell
Claude 3 Sonnet ist das Mittelklasse-Modell. Es hat sich ebenfalls gegenüber den Claude 2-Modellen verbessert, obwohl der Sprung auf den ersten Blick nicht so erheblich ist.
Verbesserungen und Kostenreduktion
Jedoch sind die Kosten für den Betrieb des Modells um mehr als das Zweifache gesunken, was auf erhebliche Verbesserungen hindeutet. Ein weiterer wichtiger Aspekt - alle Modelle der Claude 3-Reihe bieten eine bessere Mehrsprachigkeits-Unterstützung (was für internationale Unternehmen wichtig ist) und einen riesigen Kontext von 200K Token. Dies sind große Verbesserungen, die es zu feiern gilt!
Claude 3 Haiku
Claude 3 Haiku von Anthropic verdient besonderes Lob. Es ist das kleinste Modell, das es sogar geschafft hat, Claude 3 Sonnet in unseren Benchmarks zu übertreffen.
Fokus auf “Enterprise Workloads”
Anthropic erwähnt „Enterprise Workloads“ mehrmals, wenn über dieses Modell gesprochen wird. Vielleicht war diese Ausrichtung der Schlüssel dazu, bei solchen Aufgaben so gut abzuschneiden.
Das Modell selbst ist in unseren Benchmarks nicht so gut wie in ihrer PR beschrieben. Es übertrifft weder GPT-3.5 noch Gemini Pro. Das ist jedoch nicht der Punkt. Angesichts seines riesigen Kontextfensters von 200k und des attraktiven Preismodells von 1:5 (Eingabetoken kosten 5x weniger als Ausgabetoken), kann es das Standardmodell für die Arbeit mit umfangreichen Unternehmensdokumenten zu niedrigen Kosten sein.
Das Modell selbst ist 12x günstiger als Claude 3 Sonnet und 60x günstiger als Claude 3 Opus.
Gemini Pro 1.0 - vergleichbar mit Claude 3 Haiku
Gemini Pro 1.0 ist ein neues Mittelklasse-Modell von Google. Die gesamte Produktlinie umfasst Nano, Pro und Ultra.
Dieses Modell schlägt die erste Version von GPT-3.5 (die vor fast einem Jahr veröffentlicht wurde) und performt auf dem Niveau von guten Mistral 7B-Fine-Tunes bei unseren Aufgaben.
Das Modell ist auch ziemlich günstig, ungefähr vergleichbar mit Claude 3 Haiku.
Allerdings, typisch für Google, ist die Integration mit Gemini Pro 1.0 etwas schwieriger, insbesondere wenn man innerhalb der EU tätig ist. Die Kontextgröße ist ebenfalls kleiner.
Wenn Sie die Wahl haben, empfehlen wir, GPT-3.5 (v4/0125), Claude 3 Haiku oder sogar ein gutes Fine-Tune von Mistral 7B lokal mit vLLM zu verwenden.
Herausforderung beim Verstehen von Tabellen
Hier ist ein Beispiel für einen Benchmark aus der Suite für Enterprise-KI-Benchmarks. Es wird nicht mehr nur die Textmanipulation getestet, sondern eine komplexere Aufgabe.
Gegeben sei ein PDF-Dokument mit technischen Spezifikationen für LEDs. Es wird folgende Frage gestellt: Was ist die typische Peak Forward Voltage für GL538?
Wie Sie unten sehen können, steht die Zahl genau da:

Wenn Sie das PDF in ein KI-System Ihrer Wahl hochladen, wird das System daran scheitern, eine korrekte Antwort zu liefern. Selbst ChatGPT-4 mit Vision wird nicht in der Lage sein, diese Aufgabe zu bewältigen.

Probieren Sie es selbst aus!
Sie können es selbst testen, indem Sie das PDF hier downloaden und es selbst in ein KI-System Ihrer Wahl hochladen.
Das Dokument stellt für KI-Systeme aus zwei Gründen eine Herausforderung dar:
Es gibt keine Textebene in diesem PDF, nur das Bild
Die Tabelle selbst hat Lücken und ist unregelmäßig
Während in der Realität Unternehmensdokumente sogar in schlechteren Zuständen vorkommen können (ganz zu schweigen von ☕️ Kaffeeflecken auf den eingehenden Scans), macht die aktuelle Konfiguration es für von LLM angetriebene Systeme bereits sehr schwer, das Dokument zu lesen.
Was könnte ein gutes KI-getriebenes System in diesem Fall tun?
Die relevante Produktseite isolieren
Die relevante Tabelle auf der Produktseite auswählen
Das Verständnis der Tabelle auf der ausgewählten Tabelle durchführen
Dies macht die Aufgabe für GPT-4 Vision machbar.

Ausblick auf kommende Benchmarks
Dies ist eine der Aufgaben, die in den kommenden Enterprise-KI-Benchmarks vorgestellt werden. Tabellen und Spreadsheets sind das Wesen von Geschäftsprozessen, und alle guten von LLM angetriebenen Assistenten müssen sie verstehen, um nützlich zu sein. Wir werden herausfinden, welche Modelle sich dafür besonders gut eignen!

Trustbit LLM Benchmarks Archiv
Interessiert an den Benchmarks der vergangenen Monate? Alle Links dazu finden Sie auf unserer LLM Benchmarks-Übersichtsseite!