Innovation Incubator Round 1
Last year we started an Innovation Incubator. It is a learning and sharing process that tries to connect people from the different teams together. This is especially important for a remote company with people working all across Europe.
Anybody in the company can come up with an idea for an experiment - something that could be done by a team of 3-4 people working for a whole week. Each round we encourage anybody to shape and pitch their ideas, select one and then assemble a team of volunteers to get it done. Review and repeat.
The incubator rounds are stretched in time to avoid interfering with the regular projects. A “full week” doesn’t mean “working 40 hours straight in one business week”, but rather “spending one specific day per week on the innovation incubator, 5 weeks straight”.
We have already completed Round 1 of the incubator. The second Round is on its way. This is the retrospective.
Pitches
There were two experiment proposals for the round:
Design, review and publish a new exercise for the Trustbit DDD katas - offline competition.
Take apart fawkes photo cloaking algorithm in Python and attempt re-implementing it in Kotlin on JVM.
Pitches were written and presented to the company (Basecamp's ShapeUp technique is used as an inspiration for the approach). The photo cloaking algorithm was selected in the end.
Here is a PDF summary for the selected experiment. Sergey Tarasenko designed it. Ian Russel, Ahmed Mozaly and Aigiz Kunafin worked on it.
Theory
Fawkes photo cloaking algorithm takes the original photo and then tries to subtly modify it. The goal is to make the AI (a pre-trained deep neural network) believe that a different person is displayed on the photo. All photo modifications need to fit in a specific “budget” - they shouldn’t distort the photo too much.
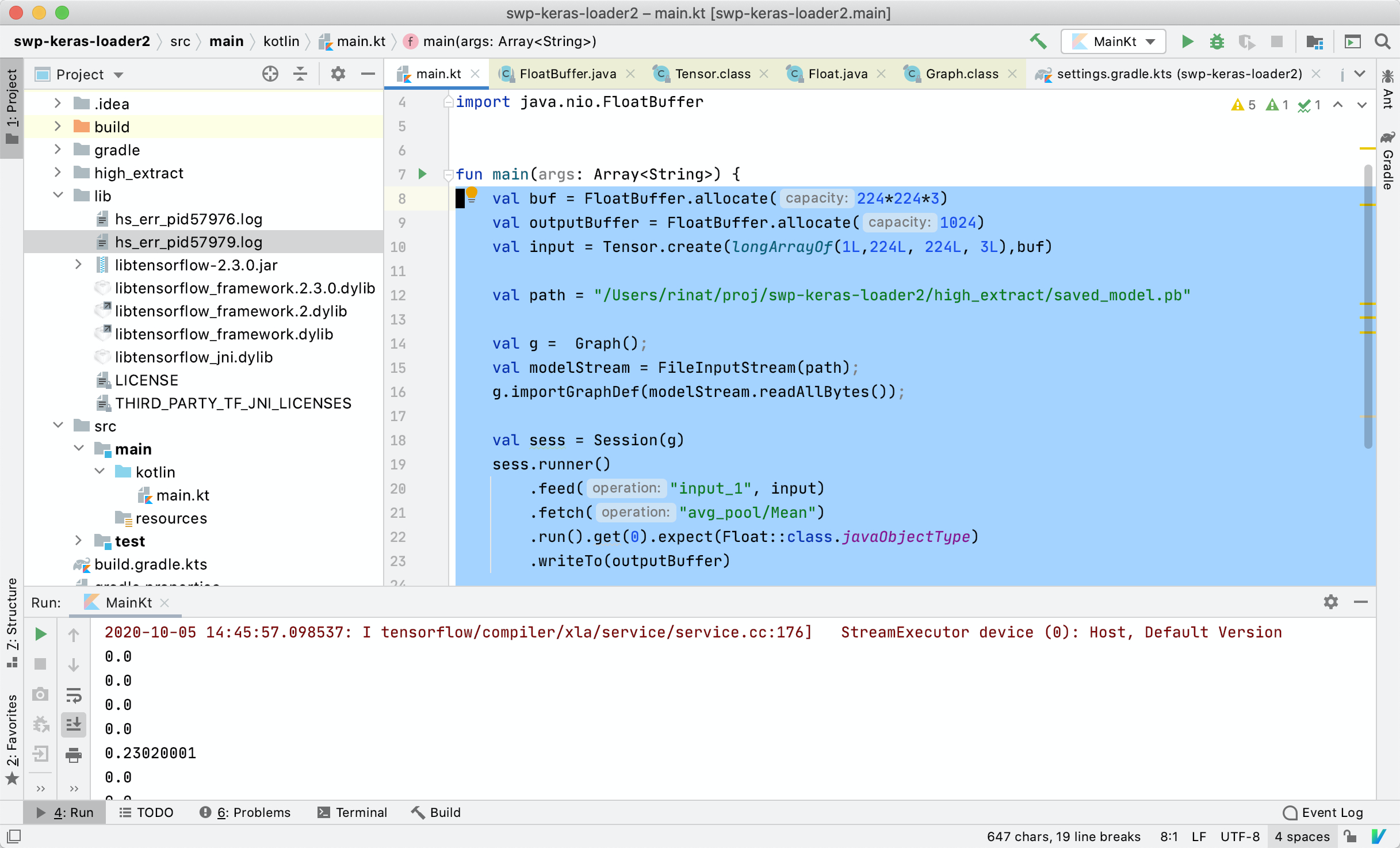
The plan was to spend some time learning the Java ML ecosystem, then take apart fawkes and quickly reimplement it in Kotlin on JVM. Fawkes uses Tensorflow with Python to run the image manipulation. Java also has a Tensorflow library that could be used from Kotlin. Nobody really knew Kotlin before, but how hard is it to pick up a new language?
Most of the assembled team didn’t have prior experience in the data science world, but there was one member that has spent the last years in that area.
How hard could it be in theory?
Practice
In practice, this round was more challenging than anticipated.
As it turned out, we’ve been trying to solve a difficult problem while learning too much at the same time: new language, a novel algorithm, data science stack, design patterns. There wasn’t enough time, plus the ML ecosystem in Java wasn’t helping much (it has a lot to catch up with Python).
Here are some of the things we have discovered along the way:
Jupyter and data science design patterns are different from the usual software development processes (e.g. business services, web applications or distributed systems).
Kotlin is a new language, that comes with a different IDE and its own ecosystem (Maven, Gradle jars etc). It took us some time to just read JSON and crop an image.
Tensorflow on Java is only partially supported, there is no Keras, and it takes some magic to just get the necessary platform-specific libraries.
The feature extractor model from fawkes in Python was stored via Keras in H5 format. It took some figuring out how to convert it to a raw Tensorflow graph loadable by the Java library. We had little prior experience with both TF and Keras.
The evolutionary algorithm was a new design pattern, so it took some time to just settle on the design and start splitting the tasks.
Fortunately, the problem was shaped to be small enough. It was possible to adjust the scope and still manage to deliver a somewhat working solution. Yet the need to constantly do that was an indication that there is a lot to learn for the planning process.
Results
At the end of 5 workdays we loaded a model in Kotlin, wrote code for the image manipulation, generating new “attack” solutions and applying them as a mask to the image. All of that was wrapped with a hand-written evolutionary algorithm.
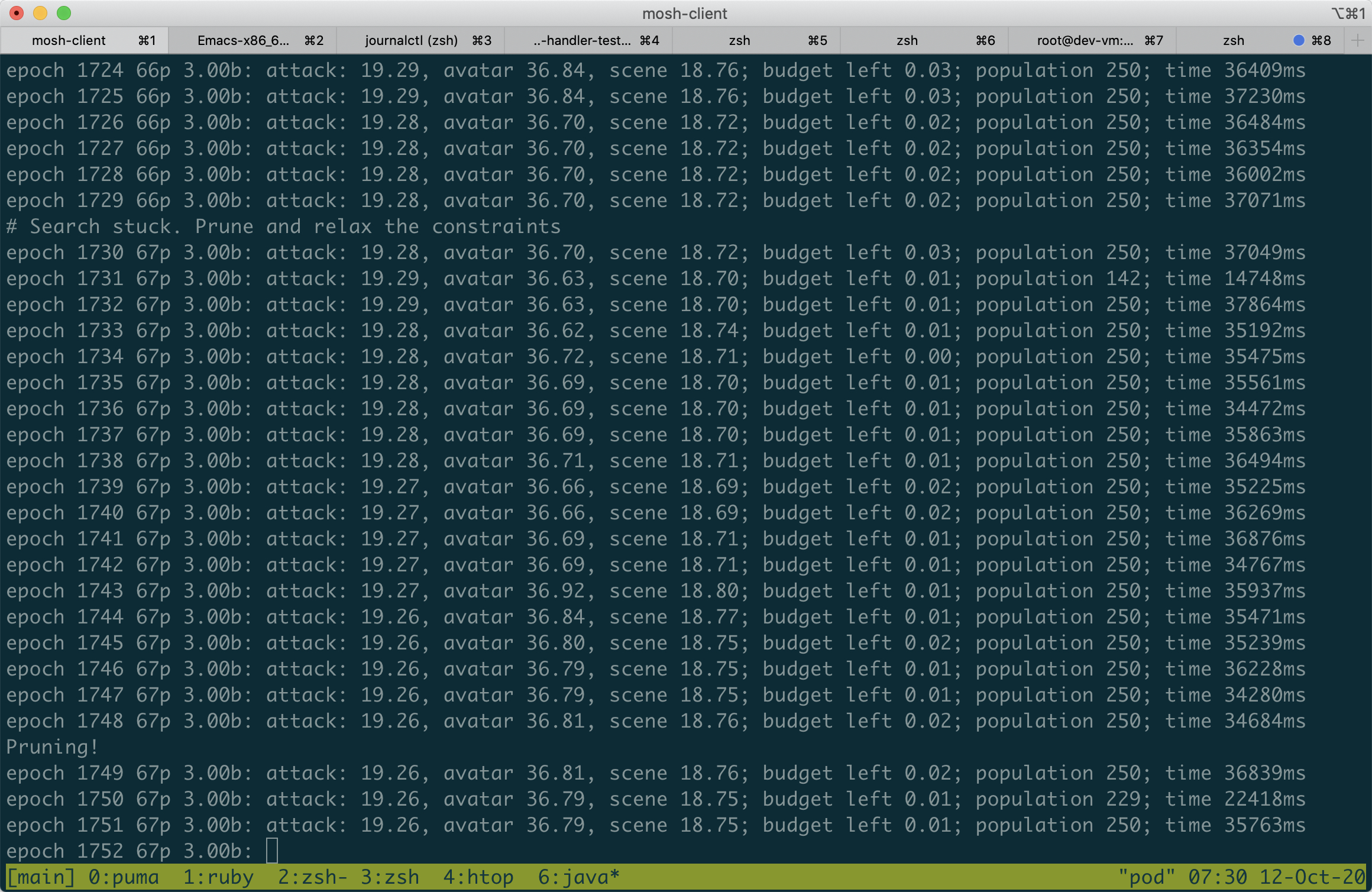
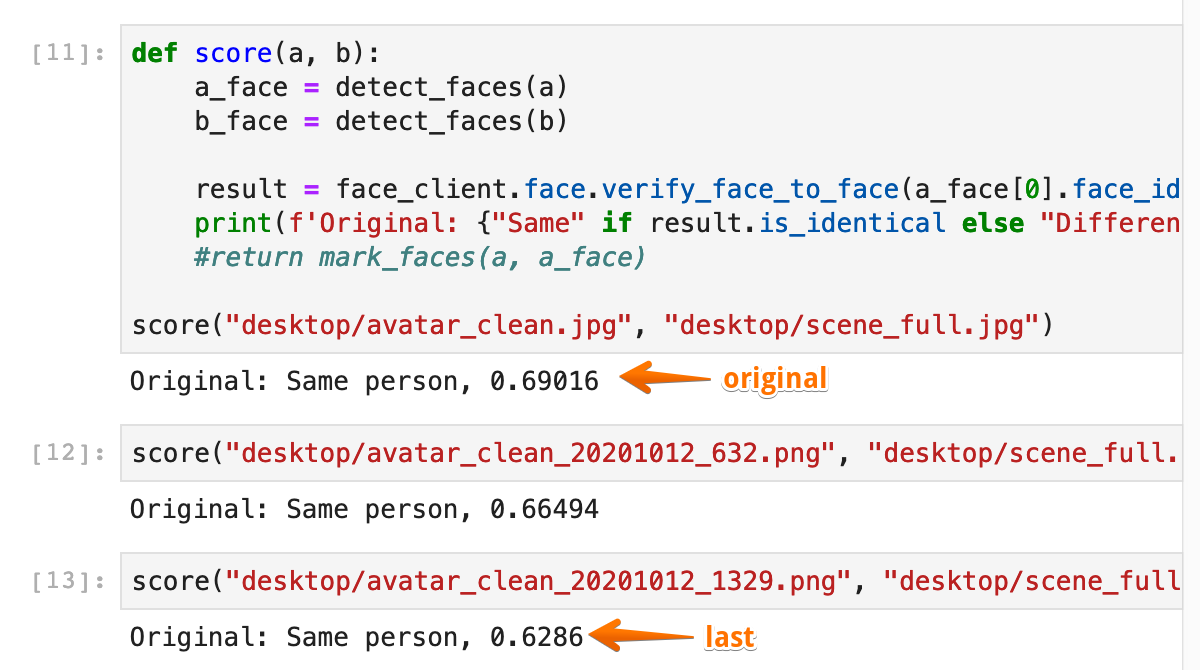
The end result was less exciting than we originally imagined. A few hours of processing made the Azure demo UI only slightly less certain about the person in the photo (from 93% confidence down to 92%). By using the face recognition API we got better improvement, but that could probably be explained by a different model running there.
We’ve learnt a lot from this round, trialed the new incubator approach and experimented with completely new technologies in 5 workdays. All that in a complete remote setup spanning three different countries with the difference of four timezones.
These results were good enough to try launching a second round of the Innovation Incubator at Trustbit. That round is almost complete by now - only one workday remains.
After the final presentation and retrospective, it will be a topic for another blog post in the series.
Acknowledgements
Ian Russel, Ahmed Mozaly, Aigiz Kunafin and Sergey Tarasenko for trialing the first round of Innovation Incubator.
Harald Beck and Ian Russel for reviewing this article.