Benchmarks für ChatGPT und Co
April 2024


Die Highlights des Monats:
Gemini Pro 1.5 von Google - Verbesserung von Pro 1.0, jetzt in der EU verfügbar
Command-R und Command-R Plus von Cohere - mittelmäßige Ergebnisse
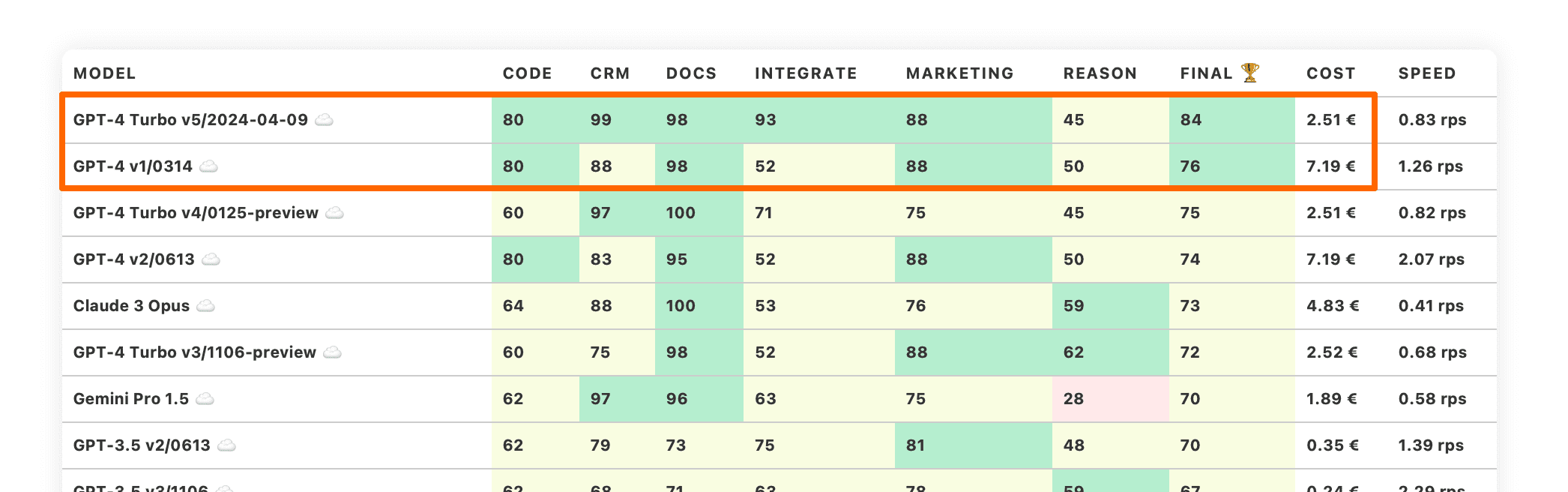
Neues GPT-4 Turbo - OpenAI hat es wieder geschafft!
Llama 3: 70B ist in Ordnung, aber 8B ist wirklich vielversprechend
Langfristige Trends
LLM Benchmarks | April 2024
Die Trustbit-Benchmarks bewerten die Modelle in Bezug auf ihre Eignung für die digitale Produktentwicklung. Je höher die Punktezahl, desto besser.
☁️ - Cloud-Modelle mit proprietärer Lizenz
✅ - Open-Source-Modelle, die lokal ohne Einschränkungen ausgeführt werden können
🦙 - Lokale Modelle mit Llama2-Lizenz
| model | code | crm | docs | integrate | marketing | reason | final 🏆 | Cost | Speed |
|---|---|---|---|---|---|---|---|---|---|
| GPT-4 Turbo v5/2024-04-09 ☁️ | 80 | 99 | 98 | 93 | 88 | 45 | 84 | 2.51 € | 0.83 rps |
| GPT-4 v1/0314 ☁️ | 80 | 88 | 98 | 52 | 88 | 50 | 76 | 7.19 € | 1.26 rps |
| GPT-4 Turbo v4/0125-preview ☁️ | 60 | 97 | 100 | 71 | 75 | 45 | 75 | 2.51 € | 0.82 rps |
| GPT-4 v2/0613 ☁️ | 80 | 83 | 95 | 52 | 88 | 50 | 74 | 7.19 € | 2.07 rps |
| Claude 3 Opus ☁️ | 64 | 88 | 100 | 53 | 76 | 59 | 73 | 4.83 € | 0.41 rps |
| GPT-4 Turbo v3/1106-preview ☁️ | 60 | 75 | 98 | 52 | 88 | 62 | 72 | 2.52 € | 0.68 rps |
| Gemini Pro 1.5 ☁️ | 62 | 97 | 96 | 63 | 75 | 28 | 70 | 1.89 € | 0.58 rps |
| GPT-3.5 v2/0613 ☁️ | 62 | 79 | 73 | 75 | 81 | 48 | 70 | 0.35 € | 1.39 rps |
| GPT-3.5 v3/1106 ☁️ | 62 | 68 | 71 | 63 | 78 | 59 | 67 | 0.24 € | 2.29 rps |
| GPT-3.5 v4/0125 ☁️ | 58 | 85 | 71 | 60 | 78 | 47 | 66 | 0.13 € | 1.41 rps |
| Gemini Pro 1.0 ☁️ | 55 | 86 | 83 | 60 | 88 | 26 | 66 | 0.10 € | 1.35 rps |
| Cohere Command R+ ☁️ | 58 | 77 | 76 | 49 | 70 | 59 | 65 | 0.85 € | 1.88 rps |
| GPT-3.5-instruct 0914 ☁️ | 44 | 90 | 69 | 60 | 88 | 32 | 64 | 0.36 € | 2.12 rps |
| Mistral 7B OpenChat-3.5 v3 0106 f16 ✅ | 56 | 86 | 67 | 52 | 88 | 26 | 62 | 0.37 € | 2.99 rps |
| Meta Llama 3 8B Instruct f16🦙 | 74 | 60 | 68 | 49 | 80 | 42 | 62 | 0.35 € | 3.16 rps |
| GPT-3.5 v1/0301 ☁️ | 49 | 75 | 69 | 67 | 82 | 24 | 61 | 0.36 € | 3.93 rps |
| Starling 7B-alpha f16 ⚠️ | 51 | 66 | 67 | 52 | 88 | 36 | 60 | 0.61 € | 1.80 rps |
| Mistral 7B OpenChat-3.5 v1 f16 ✅ | 46 | 72 | 72 | 49 | 88 | 31 | 60 | 0.51 € | 2.14 rps |
| Claude 3 Haiku ☁️ | 59 | 69 | 64 | 55 | 75 | 33 | 59 | 0.08 € | 0.53 rps |
| Mixtral 8x22B API (Instruct) ☁️ | 47 | 62 | 62 | 94 | 75 | 7 | 58 | 0.18 € | 3.01 rps |
| Mistral 7B OpenChat-3.5 v2 1210 f16 ✅ | 51 | 74 | 72 | 41 | 75 | 31 | 57 | 0.36 € | 3.05 rps |
| Claude 3 Sonnet ☁️ | 67 | 41 | 74 | 52 | 78 | 30 | 57 | 0.97 € | 0.85 rps |
| Mistral Large v1/2402 ☁️ | 33 | 49 | 70 | 75 | 84 | 25 | 56 | 2.19 € | 2.04 rps |
| Anthropic Claude Instant v1.2 ☁️ | 51 | 75 | 65 | 59 | 65 | 14 | 55 | 2.15 € | 1.47 rps |
| Anthropic Claude v2.0 ☁️ | 57 | 52 | 55 | 45 | 84 | 35 | 55 | 2.24 € | 0.40 rps |
| Cohere Command R ☁️ | 39 | 63 | 57 | 55 | 84 | 26 | 54 | 0.13 € | 2.47 rps |
| Anthropic Claude v2.1 ☁️ | 36 | 58 | 59 | 60 | 75 | 33 | 53 | 2.31 € | 0.35 rps |
| Meta Llama 3 70B Instruct b8🦙 | 46 | 72 | 53 | 29 | 82 | 18 | 50 | 7.32 € | 0.22 rps |
| Mistral 7B OpenOrca f16 ☁️ | 42 | 57 | 76 | 21 | 78 | 26 | 50 | 0.43 € | 2.55 rps |
| Mistral 7B Instruct v0.1 f16 ☁️ | 31 | 70 | 69 | 44 | 62 | 21 | 50 | 0.79 € | 1.39 rps |
| Llama2 13B Vicuna-1.5 f16🦙 | 36 | 37 | 53 | 39 | 82 | 38 | 48 | 1.02 € | 1.07 rps |
| Llama2 13B Hermes f16🦙 | 38 | 23 | 30 | 61 | 60 | 43 | 42 | 1.03 € | 1.06 rps |
| Llama2 13B Hermes b8🦙 | 32 | 24 | 29 | 61 | 60 | 43 | 42 | 4.94 € | 0.22 rps |
| Mistral Small v1/2312 (Mixtral) ☁️ | 10 | 58 | 65 | 51 | 56 | 8 | 41 | 0.19 € | 2.17 rps |
| Mistral Small v2/2402 ☁️ | 27 | 35 | 36 | 82 | 56 | 8 | 41 | 0.19 € | 3.14 rps |
| Llama2 13B Puffin f16🦙 | 37 | 12 | 38 | 48 | 56 | 41 | 39 | 4.89 € | 0.22 rps |
| Mistral Medium v1/2312 ☁️ | 36 | 30 | 27 | 59 | 62 | 12 | 38 | 0.83 € | 0.35 rps |
| Llama2 13B Puffin b8🦙 | 37 | 9 | 37 | 46 | 56 | 39 | 37 | 8.65 € | 0.13 rps |
| Mistral Tiny v1/2312 (7B Instruct v0.2) ☁️ | 13 | 39 | 57 | 40 | 59 | 8 | 36 | 0.05 € | 2.30 rps |
| Llama2 13B chat f16🦙 | 15 | 38 | 17 | 45 | 75 | 8 | 33 | 0.76 € | 1.43 rps |
| Llama2 13B chat b8🦙 | 15 | 38 | 15 | 45 | 75 | 6 | 32 | 3.35 € | 0.33 rps |
| Mistral 7B Zephyr-β f16 ✅ | 28 | 34 | 46 | 44 | 29 | 4 | 31 | 0.51 € | 2.14 rps |
| Llama2 7B chat f16🦙 | 20 | 33 | 20 | 42 | 50 | 20 | 31 | 0.59 € | 1.86 rps |
| Mistral 7B Notus-v1 f16 ⚠️ | 16 | 43 | 25 | 41 | 48 | 4 | 30 | 0.80 € | 1.37 rps |
| Orca 2 13B f16 ⚠️ | 15 | 22 | 32 | 22 | 67 | 19 | 29 | 0.99 € | 1.11 rps |
| Mistral 7B Instruct v0.2 f16 ☁️ | 7 | 21 | 50 | 13 | 58 | 8 | 26 | 1.00 € | 1.10 rps |
| Mistral 7B f16 ☁️ | 0 | 4 | 42 | 42 | 52 | 12 | 25 | 0.93 € | 1.17 rps |
| Orca 2 7B f16 ⚠️ | 13 | 0 | 24 | 18 | 52 | 4 | 19 | 0.81 € | 1.34 rps |
| Llama2 7B f16🦙 | 0 | 2 | 18 | 3 | 28 | 2 | 9 | 1.01 € | 1.08 rps |
Die Benchmark-Kategorien im Detail
Hier erfahren Sie, was wir mit den unterschiedlichen Kategorien der LLM Leaderboards genau untersuchen
-
Wie gut kann das Modell mit großen Dokumenten und Wissensdatenbanken arbeiten?
-
Wie gut unterstützt das Modell die Arbeit mit Produktkatalogen und Marktplätzen?
-
Kann das Modell problemlos mit externen APIs, Diensten und Plugins interagieren?
-
Wie gut kann das Modell bei Marketingaktivitäten unterstützen, z.B. beim Brainstorming, der Ideenfindung und der Textgenerierung?
-
Wie gut kann das Modell in einem gegebenen Kontext logisch denken und Schlussfolgerungen ziehen?
-
Kann das Modell Code generieren und bei der Programmierung helfen?
-
Die geschätzten Kosten für die Ausführung der Arbeitslast. Für cloud-basierte Modelle berechnen wir die Kosten gemäß der Preisgestaltung. Für lokale Modelle schätzen wir die Kosten auf Grundlage der GPU-Anforderungen für jedes Modell, der GPU-Mietkosten, der Modellgeschwindigkeit und des operationellen Overheads.
-
Die Spalte "Speed" gibt die geschätzte Geschwindigkeit des Modells in Anfragen pro Sekunde an (ohne Batching). Je höher die Geschwindigkeit, desto besser.
Google Gemini Pro 1.5
In unseren März Benchmarks haben wir Gemini Pro 1.0 von Google getestet. Die neuere Version Gemini 1.5 Pro zeigt eine deutlich bessere Leistung. Sie erreicht fast die Leistung des GPT-4 Turbo.
Dieses Modell schneidet besonders gut bei Aufgaben im Zusammenhang mit der Arbeit an Dokumenten und Informationen ab. Es erzielt auch fast perfekte Ergebnisse bei CRM-bezogenen Aufgaben. Komplexe Aufgaben des logischen Denkens liegen jedoch unterhalb des Niveaus von GPT-3.5.
Gemini Pro 1.5 ist auf unseren Workloads ungefähr 20-mal teurer als Pro 1.0. Dies ist angesichts der Qualitätsstufe von GPT-4 zu erwarten.
Beide Modelle sind nun in Google Vertex AI verfügbar, was sie endlich für Unternehmenskunden in der EU nutzbar macht.

Command R models von Cohere
Cohere AI ist spezialisiert auf unternehmensorientierte LLMs. Sie haben die Command-R-Modellfamilie - LLMs, die für dokumentenorientierte Aufgaben konzipiert sind: "Command R" und "Command R Plus".
Diese Modelle sind sowohl als API-SaaS als auch als herunterladbare Modelle auf Hugging Face verfügbar. Herunterladbare Modelle werden unter nicht-kommerziellen Zwecken veröffentlicht.
Das Command-R-Modell ist grob vergleichbar mit den Anthropic Claude-Modellen der ersten beiden Generationen, jedoch deutlich günstiger. Dennoch gibt es in dieser Preiskategorie bessere Modelle wie Gemini Pro 1.0 und Claude 3 Haiku.
Das Command R+ ist ein deutlich besseres Modell mit Fähigkeiten im Bereich von GPT-3.5, jedoch zu einem 2- bis 3-fachen Preis.

OpenAI erreicht mit neuen ChatGPT-4 Turbo erneut einen Meilenstein
OpenAI hat das neue GPT-4 Turbo-Modell mit der Versionsnummer 2023-04-09 veröffentlicht. Das ist aus zwei Gründen herausragend.
Erstens hat OpenAI endlich vernünftige Versionsnummern verwendet. Es hat nur ein Jahr Fortschritt gebraucht.
Zweitens übertrifft dieses Modell alle anderen Modelle in unseren LLM-Benchmarks. Es nimmt den ersten Platz mit einem deutlichen Vorsprung zum zweiten Platz ein.
Dieser Punktesprung kommt von fast perfekten Bewertungen in den Kategorien CRM und Dokumente. Außerdem hat OpenAI endlich das Problem mit der Anweisungsausführung bei wenigen Proben behoben, das dazu geführt hat, dass die Kategorie Integration so niedrig war.
GPT-4 Turbo 2023-04-09 ist derzeit unsere Standardempfehlung für neue LLM-Projekte, die das leistungsstärkste LLM benötigen, um zu starten!
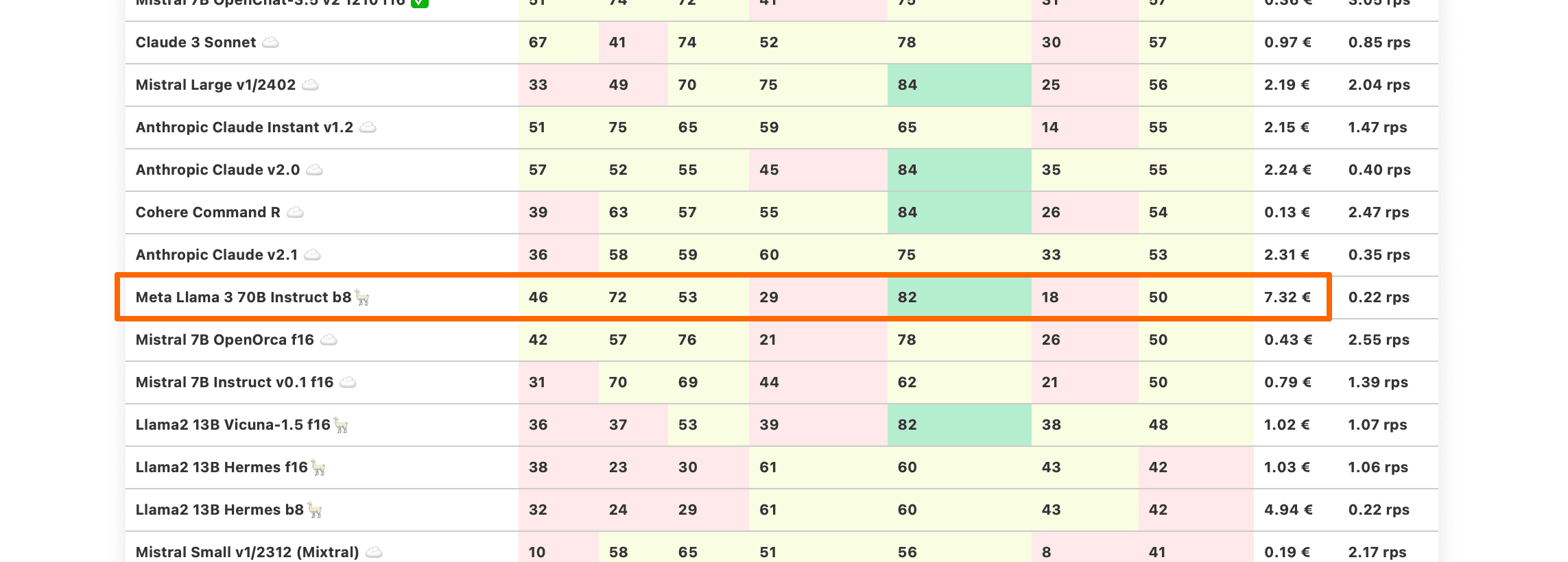
Llama 3 70B and 8B
Meta hat gerade neue Modelle in seiner dritten Generation veröffentlicht. Wir haben die instruierten Versionen von 70B und 8B auf ihre Verwendbarkeit in LLM-gesteuerten Produkten getestet.
Llama 3 70B hatte einen holprigen Start - der Upload auf HuggingFace hatte Fehler mit Tokens bei der Verarbeitung von Chatvorlagen. Sobald diese behoben waren, begann das Modell besser zu funktionieren, auf dem Niveau der alten Generationen von Anthropic Claude v2.
Beachten Sie, dass wir das b8-quantisierte Modell getestet haben, um es ordnungsgemäß auf 2xA100 80GB SMX-Karten anzupassen. Es besteht die Möglichkeit, dass f16 leicht bessere Ergebnisse liefern könnte.
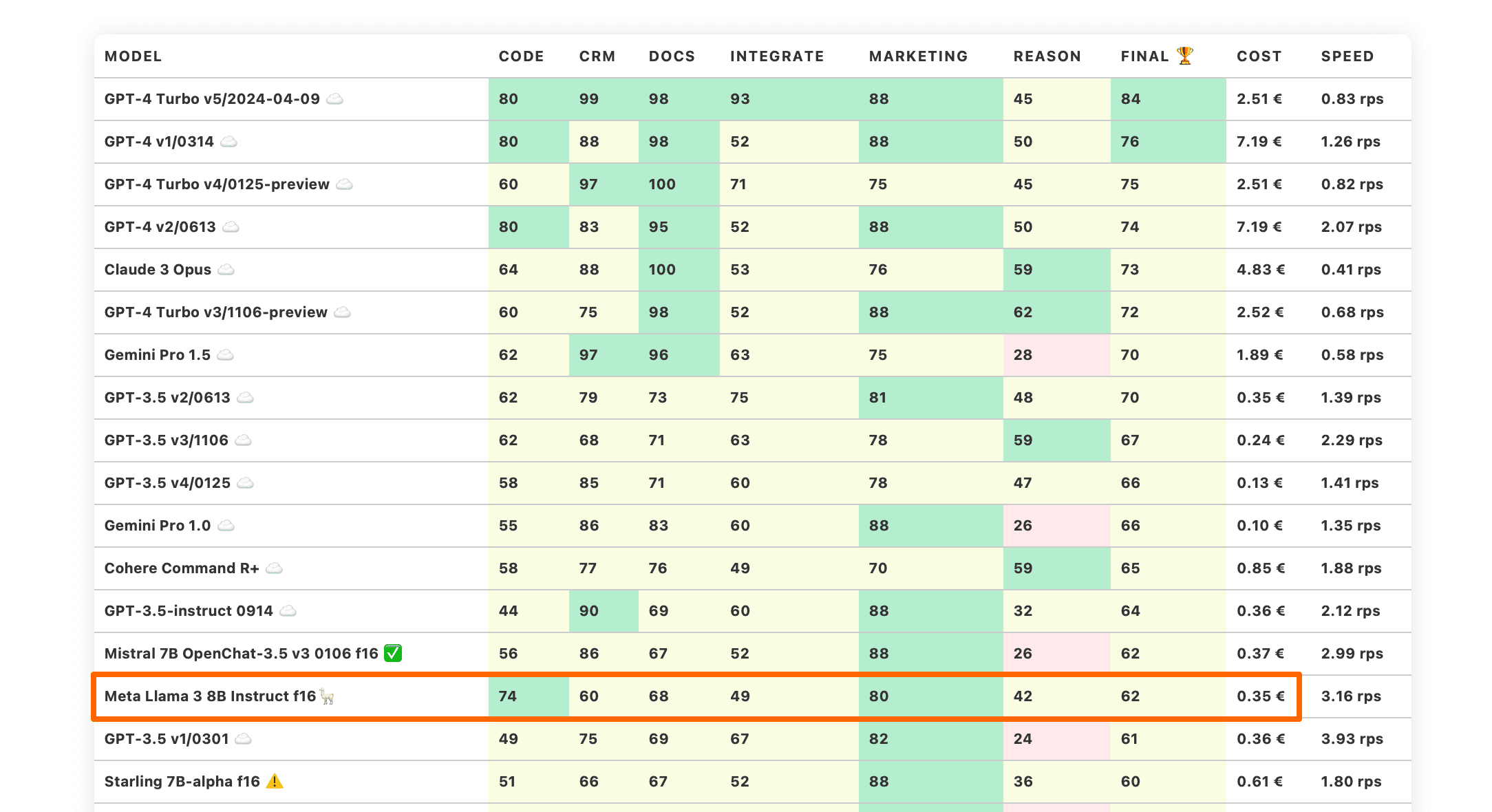
Llama 3 8B Instruct schnitt bei den Benchmarks deutlich besser ab und bringt den Stand der Technik voran, der von Meta zur Verfügung gestellt wird. Dieses Modell erzielt überraschend gute Gesamtergebnisse und eine gute "Reason"-Fähigkeit. Es besteht eine starke Chance, dass eine produktorientierte Feinabstimmung von Llama3 8B Instruct dieses Modell in die Top-10 bringen könnte.
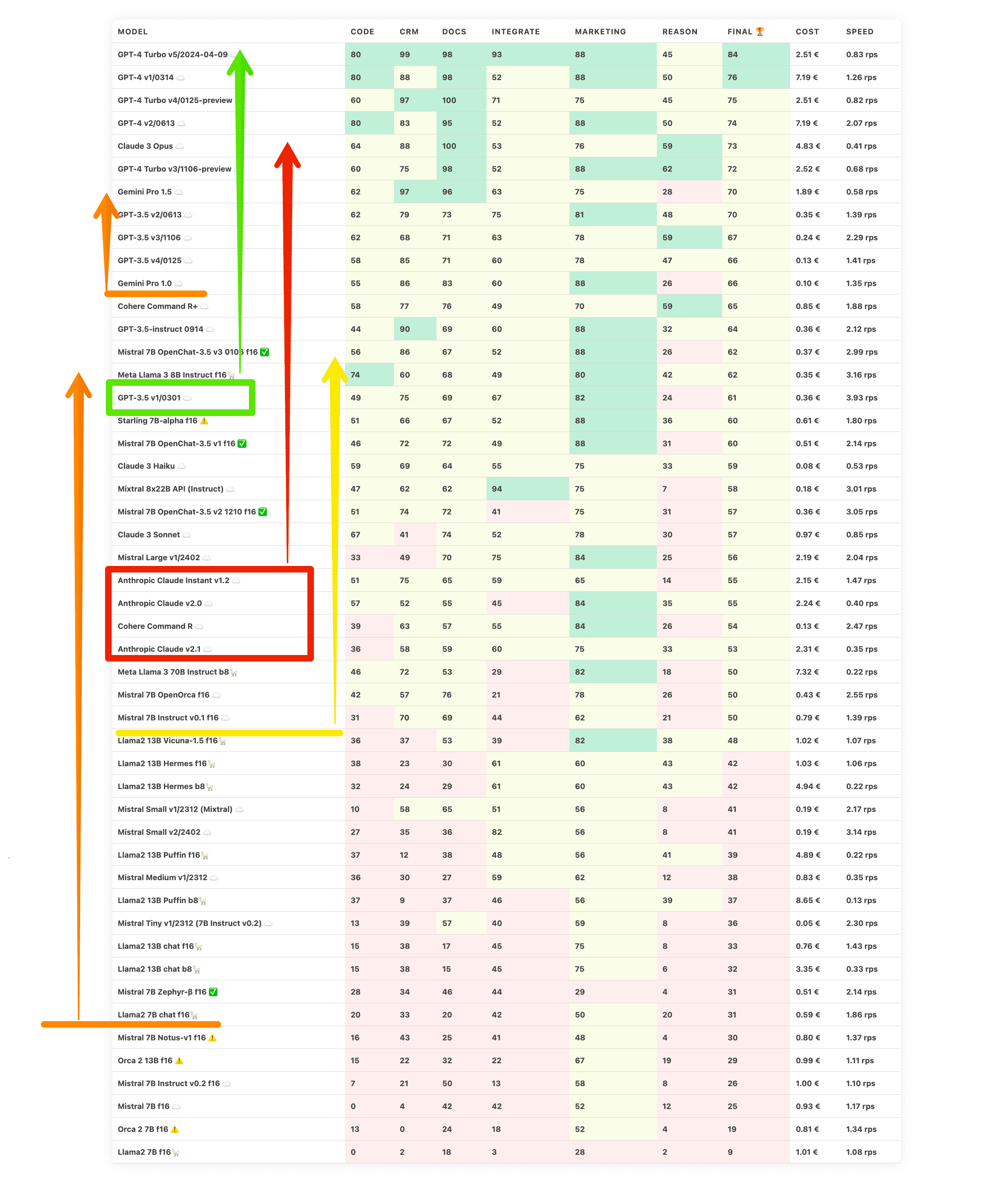
Langfristige Trends
Betrachten wir jetzt das größere Bild: Wohin entwickelt sich die Branche mit all dem?
Kostengünstiger & leistungsfähigere Modelle
Zunächst einmal werden Modelle im Allgemeinen besser und erschwinglicher. Dies ist der allgemeine Trend, den Sam Altman kürzlich in seinem Interview skizziert hat: Welche Unternehmen werden von OpenAI überrollt?
Weitere langfristige LLM Trends
Neue funktionale Fähigkeiten von LLMs
LLMs erhalten neue funktionale Fähigkeiten, die in diesem Benchmark noch nicht einmal erfasst sind: Funktionsaufrufe, Multimodalität, Datenverankerung. Die neueste Version von LLM Under the Hood erweitert dieses Thema.
Experimente mit neuen LLM-Architekturen
Unternehmen werden auch mutiger und versuchen, mit neuen LLM-Architekturen außerhalb der klassischen Transformatorarchitektur zu experimentieren. Die Mischung aus Experten wurde von Mistral populär gemacht, obwohl viele glauben, dass auch GPT sie verwendet. Rekurrente neuronale Netze erleben auch ein Comeback als Möglichkeit, die Beschränkungen der Kontextgröße zu lösen. Zum Beispiel: RWKV Language Model, Recurrent Gemma von Google Deep Mind (Griffin-Architektur).
Leistungsfähige Modelle mit geringer Rechenleistung
Was an diesen Modellen interessant ist - sie zeigen anständige Fähigkeiten, während sie wesentlich weniger Rechenleistung benötigen. Zum Beispiel haben wir einen Bericht über die 0,4B-Version von RWKV erhalten, die auf einem Low-End-Android-Telefon mit einer tolerierbaren Geschwindigkeit (nur CPU-Inferenz) läuft.
Wohin steuern wir mit all dem?
Demokratisierung der KI
Erwarten Sie, dass die Modelle weiterhin besser, günstiger und leistungsstärker werden. Sam Altman nennt dies "Demokratisierung der KI". Dies gilt sowohl für die Cloud-Modelle als auch für lokal verfügbare Modelle.
Wenn Sie gerade dabei sind, ein LLM-gesteuertes System aufzubauen, erwarten Sie, dass zum Zeitpunkt der Auslieferung des Systems das zugrunde liegende LLM wesentlich leistungsfähiger sein wird. Tatsächlich können Sie das berücksichtigen und eine langfristige Strategie darauf aufbauen.
Anpassungsfähige Systeme
Sie können das zum Beispiel tun, indem Sie LLM-gesteuerte Systeme so gestalten, dass sie transparent, überprüfbar und in der Lage sind, sich kontinuierlich an den sich ändernden Kontext anzupassen. Es gibt einige Informationen zu diesem Thema in unserem neuen Abschnitt über den Aufbau von KI-Assistenten für Unternehmen.

Trustbit LLM Benchmarks Archiv
Interessiert an den Benchmarks der vergangenen Monate? Alle Links dazu finden Sie auf unserer LLM Benchmarks-Übersichtsseite!